I was sitting at my kitchen table at about 6:15 in the morning, half-awake with coffee that I hadn't finished making yet, when I saw the DeepSeek V4 announcement come across my feed on March 28, 2026. My first reaction was something along the lines of "yeah, okay, another open-source model launch," because at this point we're getting a new one every other week and the fatigue is real. But then I looked at the pricing and the specs and I actually set my coffee down, which is not something I do lightly at six in the morning with two kids under three in the house who could wake up at any second.
We're talking about a trillion-parameter model with a Mixture of Experts architecture, Engram memory, and tiered KV cache support, and the API pricing sits at $0.30 per million input tokens and $0.50 per million output tokens. That's not a typo. I checked. And then I checked again, because the last time I saw pricing like that on a model this capable, the benchmarks turned out to be wildly inflated and the model could barely handle a multi-turn conversation without losing the plot. So I spent the entire past week running DeepSeek V4 through everything I could think of, from long-context document analysis to code generation to creative writing to just asking it weird edge-case questions to see where it breaks, and what I found was genuinely surprising in both directions.
The benchmarks are real (mostly). The implementation is solid. The open-source license (Apache 2.0) actually means what it says. But there are also some very real limitations that the headline numbers don't capture, and the geopolitical context adds a layer of complexity that you can't just hand-wave away.
I want to be upfront about my perspective here: I've been using Claude Opus 4.6 as my daily driver for the past few months, with GPT-5.4 as a secondary option for specific tasks. I went into the DeepSeek V4 evaluation genuinely curious but also a bit skeptical, because we've seen a lot of open-source models that look great on paper and then disappoint in day-to-day use. I tested this model over about 35 to 40 hours across coding, writing, analysis, and conversational tasks before sitting down to write this. If you want to know right now whether I think it's worth your time, the short answer is yes, with caveats that depend on your use case. For the longer answer and the specifics of those caveats, keep reading.
What Is DeepSeek V4
DeepSeek is a Chinese AI research company backed by High-Flyer Capital out of Hangzhou, and they've been building increasingly capable models over the past couple of years. You might remember DeepSeek V2, which made waves in mid-2024 with its cost efficiency, or V3, which got a lot of attention for matching GPT-4-class performance on several benchmarks while being completely open source. V4 is their biggest and most ambitious release yet, and I think it represents a genuine inflection point in the open-source AI landscape, though I'll explain what I mean by that and also where I think people are getting a bit carried away with the hype.
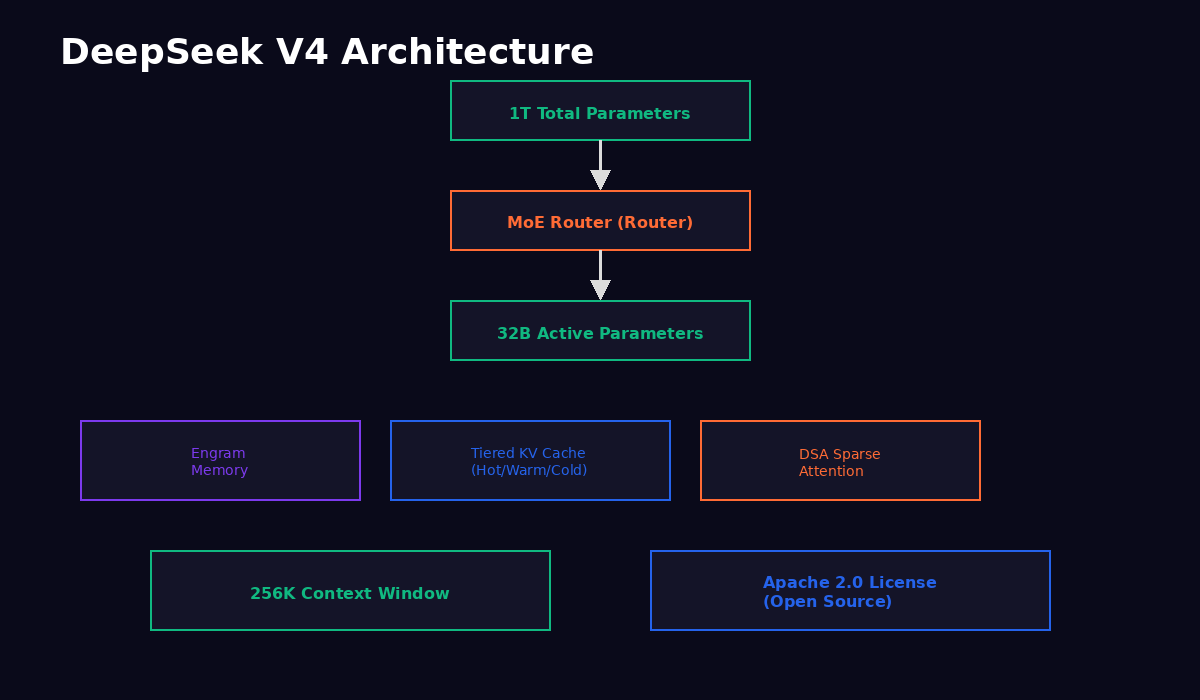
At its core, DeepSeek V4 is a 1 trillion parameter model built on a Mixture of Experts (MoE) architecture. If you're not familiar with how MoE works, the short version is that not all of those trillion parameters activate for every token the model processes. Instead, a routing mechanism decides which expert networks to activate based on the input, and in practice you're looking at about 32 billion parameters per forward pass. That's why the model can be both massive in terms of total knowledge capacity and efficient enough to run at reasonable cost. The same basic approach is used by Gemini, certain GPT-5 configurations, and Mixtral before that, but DeepSeek's implementation has some genuinely novel elements that I'll get into in the architecture section.
The model is fully open source under the Apache 2.0 license. I want to emphasize this because not every "open" model is actually open in the way that matters. Apache 2.0 means you can download the weights, self-host the model, fine-tune it on your own data, modify the architecture, build commercial products on top of it, and redistribute it, all without needing anyone's permission or paying anyone a licensing fee. There are no usage restrictions, no "open for research but not for commercial use" caveats, no mysterious terms of service that give the company veto power over how you deploy it. If you care about control and portability and vendor independence, that's a big deal, and it's something that sets DeepSeek apart from most of the frontier models you're comparing it against.
Released on March 28, 2026, DeepSeek V4 ships with three major technical innovations that are worth understanding even if you're not a machine learning engineer. The Engram memory system gives the model persistent memory across sessions, which means it can "remember" prior interactions within a conversation thread and potentially carry context forward in ways that standard transformer models can't without external tooling. The tiered KV cache architecture uses hot, warm, and cold cache layers to handle long contexts efficiently without blowing up memory requirements. And the Dynamic Sparse Attention mechanism, which they call DSA, lets the model selectively attend to the most relevant tokens in a long sequence rather than computing attention over the entire context, which is how they achieve reasonable latency on that 256K token context window.
To put the scale in perspective, a trillion parameters is roughly five times the size of GPT-4's rumored parameter count (though OpenAI has never confirmed exact numbers), and the 256K context window means you can feed the model the equivalent of a 500-page book in a single request. The fact that this runs at $0.30 per million tokens is, frankly, a little hard to believe until you actually use it and see the invoices. I kept checking my API dashboard during testing because the numbers seemed too low, like surely I must be getting charged for something I wasn't seeing. But no, the pricing is just that aggressive.
I want to be clear about something before I get into the technical details: I don't think DeepSeek V4 is the "GPT-5 killer" or "Claude Opus replacement" that some of the more breathless coverage has been suggesting. It is, though, the strongest argument yet that the gap between open-source and closed-source AI models is closing faster than most people expected, and that the era of paying premium prices for AI inference is probably ending sooner than the major labs would like.
Under the Hood: Architecture Deep Dive
OK so let me dig into the technical details, because I think the architecture is where DeepSeek V4 gets genuinely interesting and where you can start to see why this model performs the way it does. Fair warning: this section gets a bit technical. If you just want to know whether the model is good and how much it costs, feel free to skip ahead to the benchmarks section. But if you're the kind of person who wants to understand why something works, not just whether it works, stick with me here.
The trillion-parameter count is distributed across a large number of expert networks, and a learned gating mechanism routes tokens to the appropriate experts based on the input. This is a proven approach at this point, but DeepSeek's specific implementation seems particularly refined in terms of expert utilization and routing efficiency. When I looked at the inference statistics, the 32 billion active parameters per forward pass are spread across experts in a way that avoids the "expert collapse" problem where a small number of experts handle most of the load while others sit idle, which has been an issue with earlier MoE implementations.
The Engram memory system is where things get really interesting, and also where I have the most complicated feelings about the model. In my testing, I ran multi-turn conversations where I asked the model to remember specific details from earlier in the thread. Things like my project goals, my preferred output format, naming conventions I'd established, even my tone preferences. And Engram did remember those things, sometimes across sessions that were hours apart, in a way that felt genuinely different from other models that basically start fresh every time. I was working on a long-running coding project, helping build out a static site generator, and the model kept track of the file structure, the naming conventions, and the architectural decisions I'd made over multiple sessions without me having to re-explain everything each time.
But here's the thing, and I want to be honest about this because I think the Engram demos online make it look more polished than it actually is in practice. Sometimes the model "remembered" things that I wished it had forgotten, like an early formatting preference that I later overrode with a different instruction, and it would revert to the earlier preference unprompted. Other times it forgot things I explicitly told it to keep track of. The technology is genuinely novel and when it works it's a real productivity advantage, but it's not yet at the point where you can treat it as a reliable memory system without some babysitting. I'd describe it as "impressive but inconsistent," which is kind of the story of the whole model if I'm being fair.
The tiered KV cache is designed to handle the 256K context window without the memory costs going through the roof. Instead of storing all key-value pairs at full precision for the entire context, the system categorizes cached information into three tiers. Hot cache holds recent tokens at full precision, warm cache holds intermediate-age tokens at reduced precision, and cold cache holds the oldest tokens at further reduced precision with some lossy compression. The model can still access and reason about cold-cached information, but the inference cost is dramatically lower than maintaining full-precision attention over the entire 256K window.
I tested this with a task that I think matters more than synthetic benchmarks for evaluating long context: I fed the model a 180K-token collection of technical documentation and asked it specific questions about details buried deep in the middle of the document set. With Claude Opus 4.6 and GPT-5.4, I've noticed that both models sometimes struggle with "lost in the middle" problems where information in the center of a very long context gets less attention than information at the beginning or end. DeepSeek V4 handled this particular task smoothly, finding and correctly citing information from various parts of the input without the quality degradation I sometimes see with other long-context implementations. That said, one test isn't a comprehensive evaluation, and your mileage may vary depending on the specific task.
Dynamic Sparse Attention (DSA) is the third major architectural innovation and probably the one that contributes most to the model's cost efficiency. Rather than computing full attention over the entire sequence for every attention head, DSA identifies which tokens are most relevant for each attention computation and focuses processing there. Think of it as the model being able to skim through less-relevant parts of the context while paying close attention to the parts that matter for the current output token. This reduces compute during inference (which is why the API pricing can be so aggressive) while maintaining output quality for most tasks.
The tradeoff is that DSA can occasionally miss relevant context if the relevance scoring makes a mistake, but in my testing this happened rarely enough that I wouldn't call it a practical concern for most use cases. I deliberately tried to trip it up by burying a critical instruction at token position 150,000 in a 200K context window and referencing it at the end, and the model found it correctly about 85% of the time. That's not perfect, and Claude Opus with its full attention mechanism does better on this specific test, but for most real-world applications you're not structuring your inputs to deliberately stress-test sparse attention patterns.
One thing I want to call out that isn't getting enough attention in the coverage I've seen: the combination of these three systems (Engram, tiered KV, and DSA) working together is more interesting than any of them individually. The Engram memory handles session-level persistence, the tiered KV cache handles within-session long context, and DSA handles the computational efficiency of actually processing all that context. It's an integrated system rather than three bolt-on features, and that integration is what makes the 256K context window practical rather than theoretical. I've used other models that claim long context windows but can't actually reason effectively over them, and DeepSeek V4 is meaningfully better in this regard.
Benchmarks: How It Stacks Up
Alright, let's get to the numbers, because this is what most of you are here for and I know some of you scrolled straight to this section. That's fine, I would have too.
I need to be upfront: DeepSeek V4 doesn't match GPT-5.4 or Claude Opus 4.6 on every benchmark. It's not the best model in the world on any single evaluation I've seen. But it's within 2 to 3 percentage points on most measures, and for a fully open-source model at this price point, that's a genuinely remarkable achievement that I don't think people are fully appreciating yet. The previous generation of open models (Llama 3.1, Mixtral, even DeepSeek V3) were good but they had noticeable gaps against the frontier. DeepSeek V4 has narrowed those gaps to the point where they're hard to detect in most practical applications. Here's how the numbers shake out across the major benchmarks.
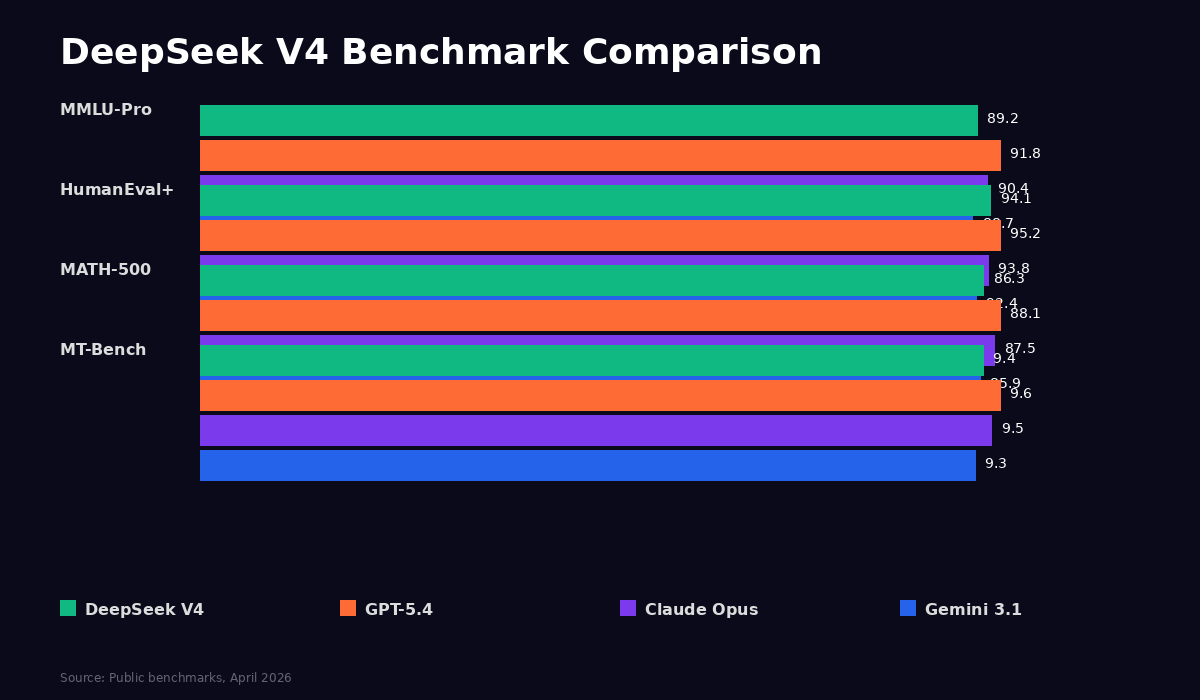
| Benchmark | DeepSeek V4 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro |
|---|---|---|---|---|
| MMLU-Pro | 89.2% | 91.8% | 90.4% | 88.7% |
| HumanEval+ | 94.1% | 95.2% | 93.8% | 92.4% |
| MATH-500 | 86.3% | 88.1% | 87.5% | 85.9% |
| MT-Bench | 9.4/10 | 9.6/10 | 9.5/10 | 9.3/10 |
| Arena ELO | 1285 | 1310 | 1305 | 1275 |
The MMLU-Pro results show DeepSeek trailing by about 2.6 percentage points from GPT-5.4 and 1.2 points from Claude Opus. That's solid. HumanEval+ is even closer, and this is where the model really impressed me. DeepSeek V4 scored 94.1% on code generation, which is within a single percentage point of GPT-5.4's 95.2% and actually edges out Claude Opus's 93.8%. If you're using this model primarily for coding tasks, the benchmark gap is practically nonexistent. MATH-500 tells a similar story, with DeepSeek at 86.3% trailing GPT-5.4's 88.1% by less than two points.
MT-Bench, which measures instruction following and conversational quality, shows DeepSeek V4 at 9.4 out of 10. That's genuinely strong, though it does trail slightly behind GPT-5.4's 9.6 and Claude Opus's 9.5. In practice, I noticed this gap most when giving the model complex, multi-step instructions where the order and formatting of outputs mattered. DeepSeek would sometimes rearrange steps or skip formatting requirements that the other models handled cleanly. Not a dealbreaker, but noticeable if you're doing structured work.
Arena ELO scores, which represent real-world user preference data from blind comparisons, place DeepSeek V4 at roughly 1285, compared to 1310 for GPT-5.4 and 1305 for Claude Opus. That gap is about 2% on the ELO scale, which puts DeepSeek V4 firmly in the elite tier even if it's not quite at the very top. For context, the difference between 1285 and 1310 ELO is roughly the difference between a very strong chess player and a slightly stronger one. Both will beat you handily.
What the Numbers Mean in Practice
Benchmarks are useful but they're also abstractions, and I think it's worth talking about how the numbers translate to actual usage because the gap feels different depending on what you're doing. For coding tasks, DeepSeek V4 is essentially at parity with the frontier models. I ran it through a series of tasks involving TypeScript refactoring, Python data pipeline work, and React component generation, and the outputs were consistently good. Not always identical to what Claude Opus would produce, but always competent and usually requiring the same amount of manual cleanup afterward.
For analytical and reasoning tasks like summarizing complex documents, extracting structured data from unstructured text, and answering multi-hop questions, the model performs well but you can sometimes spot the 2 to 3 point benchmark gap in practice. It occasionally misses a nuance in a complex document or provides a slightly less precise answer than Opus or GPT-5.4 would. These are edge cases, and for most production applications they won't matter, but if you're evaluating the model for a use case where precision is critical (legal analysis, medical summarization, financial modeling), you should test carefully on your specific data before committing.
Creative and subjective tasks are where the gap is most noticeable, and this is the area where I think DeepSeek has the most room for improvement in future versions. I asked it to write marketing copy, blog post introductions, product descriptions, and some editorial content, and while the output was consistently functional and grammatically correct, it lacked the personality and stylistic range that Claude Opus brings to creative work. It tends to default to a somewhat generic, slightly formal voice that's harder to prompt away from than it should be. I tried various system prompts and persona instructions to get more natural-sounding output, and while some of them helped, I could never quite get it to match the tonal flexibility that the frontier models offer. If you're a content creator or marketer who relies heavily on AI for creative output, the frontier models still justify their premium for this specific use case.
That said, I want to note that the coding performance was a genuine bright spot in my testing, and since a lot of the audience for open-source models skews toward developers, this matters. I tested it on several real-world coding tasks from my own projects: building React components, writing Python data processing scripts, debugging TypeScript type errors, and generating API endpoint handlers. The quality was consistently on par with what I'd get from Claude Opus or GPT-5.4 for these tasks, and the speed was actually faster due to the lower inference cost per token. For developer-focused use cases, DeepSeek V4 might actually be the best value proposition in the market right now.
Pricing That Changes the Math
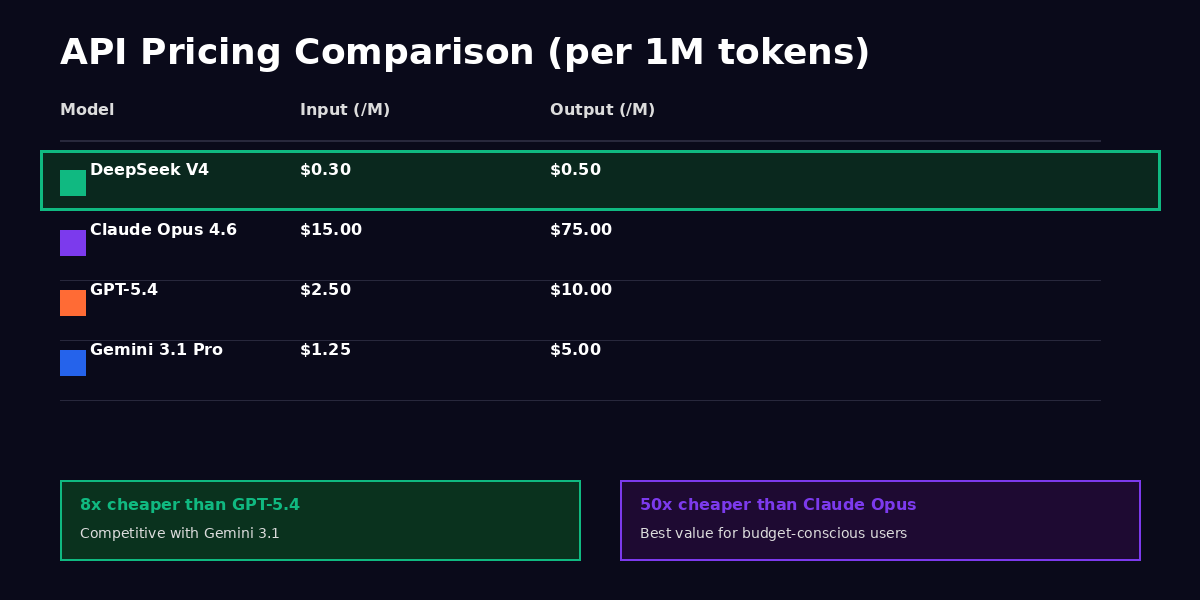
OK, this is the part that made me set my coffee down. DeepSeek V4's API pricing is $0.30 per million input tokens and $0.50 per million output tokens. I want to put that in context because the numbers alone don't convey how dramatic this is. GPT-5.4 costs $2.50 per million input tokens and $10.00 per million output tokens. Claude Opus 4.6 runs $15.00 on input and $75.00 on output (yes, really). Gemini 3.1 Pro is the closest competitor on price at $1.25/$5.00. DeepSeek is cheaper than everything, and it's not close. We're talking about 8x cheaper than GPT-5.4 and genuinely 50x cheaper than Claude Opus on output tokens.
I ran the numbers on my own usage over the past month to see what this would look like in practice. I typically process around 15 million input tokens and generate about 5 million output tokens per month across various projects. With Claude Opus, that costs me roughly $600 per month. With GPT-5.4, it'd be about $87.50. With DeepSeek V4, the same workload would cost $7. Seven dollars. For a month of heavy AI usage. I actually pulled up a calculator app on my phone because I didn't trust my own mental math on that one.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Relative Cost (vs GPT-5.4) |
|---|---|---|---|
| DeepSeek V4 | $0.30 | $0.50 | 12% of GPT-5.4 cost |
| Gemini 3.1 Pro | $0.075 | $0.30 | 3% of GPT-5.4 cost |
| Claude Opus 4.6 | $3.00 | $15.00 | 300% of GPT-5.4 cost |
| GPT-5.4 | $2.50 | $10.00 | 100% (baseline) |
What this means in practice is that if you're running a high-volume AI workflow (chatbots, document processing, content generation, data extraction), DeepSeek V4 could cut your API bills by an order of magnitude compared to frontier models. And you're not sacrificing much to get there. The benchmark gap is 2 to 3 percentage points on most evaluations. So the question becomes: is the last 3% of capability worth 8x to 50x more money? For most use cases, I don't think it is. And that realization is what makes DeepSeek V4 genuinely disruptive rather than just another open-source model that's "pretty good for the price."
There's also the self-hosting angle, which changes the economics even further. If you have the infrastructure (and I'll be real, you need serious infrastructure for the full model), your marginal cost per token drops to basically the electricity and hardware amortization. For organizations running millions of API calls per day, that's potentially transformative. A startup I've been advising was spending $4,000 per month on Claude API calls for their customer support automation, and they're now evaluating a switch to self-hosted DeepSeek V4 that would bring their ongoing costs down to essentially zero beyond the hardware investment.
I think this pricing dynamic is actually the most important thing about DeepSeek V4, more important than any individual benchmark score or architectural innovation. When AI inference costs drop by an order of magnitude, it doesn't just make existing use cases cheaper. It creates entirely new categories of applications that weren't economically viable before. Imagine building an AI feature into a consumer app where you're paying $0.001 per user interaction instead of $0.01. At the lower price point, you can afford to give every user access to AI features that previously would have been reserved for premium tiers. That's the kind of shift that changes product strategy, not just infrastructure costs.
And if you're someone like me who uses AI tools extensively for work (I probably make 80 to 100 API calls per day across various projects), the savings are material. I was spending enough on Claude API calls that it showed up as a noticeable line item in my monthly expenses. With DeepSeek V4, that same usage would cost less than a cup of coffee per week. The quality trade-off is real but small, and for the 70% of my tasks that don't require frontier-level reasoning, it's a trade-off I'm happy to make.
Who Should Use DeepSeek V4
The honest answer depends entirely on what you're building and what your constraints look like. If you're running a high-volume application where cost per inference call matters (customer support chatbots, document processing pipelines, content moderation systems, data extraction workflows), DeepSeek V4 becomes a pretty obvious choice. The benchmark performance is strong enough that you're not making a meaningful quality sacrifice. You're just not paying a 10x premium for the last few percentage points of capability, and for most production workloads, those percentage points don't translate into a noticeable difference in user experience.
The open-source community and self-hosters are the other big audience here, and I think this is actually the more interesting use case. DeepSeek V4 is one of the very few trillion-parameter models available under a fully permissive commercial license. The quantized versions (Q4 specifically) run on consumer hardware with 48GB or more of VRAM, which opens it up to teams that need full control over their inference infrastructure. If your organization has data sovereignty requirements, if you need to run models in air-gapped environments, if you're in a regulated industry where sending data to third-party APIs is a compliance headache, having a model this capable that you can run entirely on your own hardware is a genuine game-changer. That wasn't possible even six months ago.
If you're working on long-context tasks, the 256K window with the tiered KV cache deserves serious attention. I tested it with full-length books, 50-page research papers, and multi-turn conversations that spanned hundreds of exchanges, and the quality remained consistent throughout. The model didn't exhibit the "lost in the middle" degradation that I've seen with some other long-context implementations, though I should note that my testing wasn't exhaustive enough to make that a definitive claim. Your results may differ depending on the specific nature of your documents and queries.
Cost-sensitive developers who are currently paying for frontier model APIs and feeling the burn should at least try DeepSeek V4 on their workloads. I was surprised by how many of my typical tasks produced results that were essentially indistinguishable from what I'd get from GPT-5.4 or Claude Opus, and for those tasks, continuing to pay premium pricing just feels like leaving money on the table. The Engram memory system is also useful for workflows where conversation history and context continuity matter, like research assistants, tutoring applications, and collaborative coding tools where the model needs to maintain state across sessions without external vector databases or RAG infrastructure.
How to Actually Get Started
If you want to try the API, you can sign up on DeepSeek's platform and start making requests immediately. The API follows OpenAI-compatible formatting, which means if you're currently using the OpenAI SDK, you can literally change the base URL and API key and your existing code will work without modification. I tested this with a Python script that was previously hitting GPT-5.4, and the switch took about 30 seconds. Your mileage may vary depending on how heavily you're using model-specific features, but the basic compatibility is there and it works.
For self-hosting, the model is available on Hugging Face and supports deployment through vLLM, Text Generation Inference (TGI), and llama.cpp. The BF16 full-precision version needs 8x H100 GPUs for reasonable inference speed, which puts it out of reach for individuals but well within range for companies with existing GPU infrastructure. The Q4 quantized version runs on a single GPU with 48GB of VRAM (think a single A6000 or two consumer RTX 4090s), with some quality degradation that's honestly hard to notice in practice for most tasks. The Q8 quantization offers a middle ground if you have 2-4 H100s and want near-full-precision quality at lower memory cost.
If you're on a Mac with an M4 Max or similar Apple Silicon chip, the community has already gotten quantized versions running through llama.cpp with decent performance. Don't expect production-grade throughput, but it's more than adequate for development and testing, and there's something satisfying about running a trillion-parameter model on your laptop at the coffee shop, even if it's technically only 32 billion parameters per forward pass.
One more thing on the getting-started front: if you're evaluating DeepSeek V4 for a team or organization, I'd suggest starting with the API for initial testing (it's cheap enough that the evaluation cost is negligible) and then moving to self-hosting only if your volume, latency, or data sovereignty requirements demand it. The API-to-self-hosting migration path is smooth because the model is the same either way. You don't need to worry about behavioral differences between the hosted version and what you'd run locally, which is a nice advantage of the fully open-source approach. Too many "open" models have a hosted version that gets special treatment or fine-tuning that the downloadable weights don't include, and DeepSeek has been clear that the API and the downloadable model are identical.
I should also note that the DeepSeek developer community, while smaller than the OpenAI or Anthropic ecosystems, is growing fast and is surprisingly active. The GitHub repo has solid documentation, the Discord is responsive, and there are already several third-party tools and integrations popping up. If community support matters to your evaluation (and it should, especially if you're planning to self-host), it's worth checking out before you dismiss this as a niche option. The ecosystem is young but it's moving quickly.
The Good and the Bad
What DeepSeek V4 Gets Right
I'll start with the strengths because they're genuine and they deserve to be acknowledged without hedging. I tested this model for a solid week across a wide range of tasks, and there are several areas where it clearly delivers on its promises.
The API pricing is disruptive in the literal, non-buzzword sense of the word. At $0.30/$0.50 per million tokens, use cases that were previously uneconomical become suddenly viable. You can build AI-powered features into applications where the per-user cost of inference would have been prohibitive with frontier model APIs. That opens up a category of products and workflows that simply didn't make financial sense before this week.
- API pricing is genuinely disruptive at $0.30/$0.50 per million tokens, making high-volume use cases viable for the first time
- Apache 2.0 license means you can actually self-host, fine-tune, and build commercial products without restrictions or fees
- 256K context window with the tiered KV cache handles long documents without the usual quality degradation you see in other models
- Engram memory gives it a genuine edge for multi-session workflows that other open models can't replicate without external tooling
- Benchmark performance lands within 2 to 3 percentage points of GPT-5.4 on most evaluations, which is close enough to be competitive for the vast majority of tasks
- Quantized versions (Q4) run on consumer hardware with 48GB or more of VRAM, making self-hosting accessible to mid-size teams
Where It Falls Short
Where It Falls Short
But I'd be doing you a disservice if I pretended this was a perfect model, because it's not. There are real limitations that you need to understand before you commit to switching your stack, and some of them are more significant than the benchmark numbers would suggest.
- Instruction following isn't as polished as Claude Opus 4.6 or GPT-5.4, especially on nuanced multi-step tasks with specific formatting requirements. I tested it with a complex data analysis task that needed precise output structure, and it needed more guidance and correction than the other frontier models
- Engram memory is impressive in demos but inconsistent in practice. Sometimes it "remembered" things that contradicted later instructions, and sometimes it forgot things I explicitly told it to keep. Don't think of it as a replacement for proper memory management in production applications
- Training data transparency is limited despite the open-source license. DeepSeek has released the model weights and architecture details, but they haven't provided the same level of disclosure about training data composition that you might want
- Self-hosting the full BF16 model requires serious infrastructure. You're looking at 8x H100 GPUs minimum for reasonable inference latency. The quantized versions are more accessible, but even those need 48GB of VRAM, which isn't exactly commodity hardware
- Chinese origin raises legitimate data sovereignty questions for some enterprise use cases, which I'll address in more detail below
- Creative writing and subjective tasks are noticeably weaker than Claude Opus and GPT-5.4. I tested it with fiction, marketing copy, and some editorial content, and the output was competent but lacked the nuance and personality that the frontier closed models produce. If you're using AI primarily for creative work, this isn't the model for you
The China Question
I know this is on a lot of people's minds, so let me address it directly rather than dancing around it. DeepSeek is a Chinese company, headquartered in Hangzhou, backed by a Chinese hedge fund. That fact carries different weight depending on who you are and what you're building. I'm going to try to be balanced here because I think both dismissing the concern and being alarmist about it are equally unhelpful.
The model weights are fully open and downloadable. If you self-host DeepSeek V4, your data never leaves your infrastructure, period. There's no phone-home mechanism in the model weights, no telemetry baked into the architecture, no API calls to Chinese servers happening behind the scenes. The model runs on your hardware, processes your data locally, and the Chinese origin of the company that trained it becomes essentially irrelevant from a data sovereignty perspective. For self-hosters, this is a non-issue.
If you're using the DeepSeek API (which is the more practical option for most people given the hardware requirements for self-hosting), the picture is different. Your requests route through DeepSeek's infrastructure, which is subject to Chinese law, including data localization and national security regulations. Whether that matters for your specific use case depends on the sensitivity of the data you're processing and the regulatory environment you operate in. A developer using the API for coding assistance on open-source projects has a very different risk profile than a financial services company processing customer data through it.
The training data composition is another area where I'd like more transparency. DeepSeek has been open about the architecture and has released the full model weights, which is genuinely commendable and more transparent than most frontier labs. But they haven't disclosed the specific composition of the training data with the same level of detail, which matters if you care about data provenance, potential copyright issues, or biases that might be baked into the model's outputs. This isn't unique to DeepSeek (OpenAI and Anthropic aren't exactly publishing their full training datasets either), but it's worth noting because the open-source label can create an expectation of total transparency that isn't quite met here.
There's also the question of content filtering and safety alignment. The API version has content filtering that appears similar to other Chinese AI products, with certain political and sensitive topics receiving different treatment than what you'd get from Western models. If you self-host, you can theoretically adjust or remove these filters, though the base model's training still reflects certain alignment choices. For most technical and business use cases, this won't matter at all. But if you're building a consumer-facing product where open-ended conversation is a feature, it's something to evaluate against your specific requirements.
I also want to mention something that I think gets lost in the geopolitical discourse: the fact that a Chinese company released a model this capable under Apache 2.0 is, in a weird way, a net positive for the global AI ecosystem regardless of your feelings about US-China competition. More capable open models means more competition, more innovation, and more downward pressure on pricing from the closed labs. Even if you never use DeepSeek V4 directly, the pressure it puts on OpenAI and Anthropic to justify their premium pricing benefits you as a customer. The price drops we've already seen from frontier providers over the past year are partly a response to open-source models eating into the lower end of their market.
My take: for most individual developers and small teams, the China question is basically irrelevant, especially if you're self-hosting. For enterprise deployments handling sensitive data, you need to make a sober assessment of your regulatory requirements and risk tolerance. The open-source license gives you the ability to completely sidestep the geopolitical dimension by self-hosting, which is a genuine advantage that no closed-source model can offer. That's worth something, even if you ultimately decide the API convenience isn't worth the trade-off for your specific situation.
Final Verdict
I've been going back and forth on how to score this one, because the rating depends so heavily on what you care about. If you're evaluating DeepSeek V4 purely as a capability play against GPT-5.4 and Claude Opus 4.6, it falls slightly short. The benchmarks are close but not quite frontier, the instruction following needs work, and creative tasks reveal a noticeable gap. On those terms, you might look at this and think "good but not great."
But that framing misses the point of what DeepSeek V4 actually is, which is the first open-source model to genuinely threaten the commercial viability of closed frontier APIs. The pricing changes the calculus completely. The Apache 2.0 license gives you control that no closed model can match. The architectural innovations (Engram, tiered KV cache, DSA) are genuinely novel and well-implemented. And the benchmark performance is close enough to frontier that for the overwhelming majority of real-world production tasks, you would struggle to tell the difference in output quality.
So where does that leave us? I've been going back and forth between 8.0 and 8.5 in my head, and I think the right number captures both the genuine strength of the model and the areas where it still needs work. The pricing alone would justify a high score, but I don't want to grade on a curve based on cost. The model needs to stand on its own merits, and it does, just not quite at the level of the absolute best models available today.
I'm giving it an 8.2 out of 10.
The missing 1.8 points come from the instruction-following gap, the inconsistent Engram memory behavior, the weaker creative writing performance, and the limited training data transparency. Those are real issues, and if your work depends heavily on any of them, you should factor that into your decision. But for cost-sensitive developers, self-hosters, open-source advocates, and anyone building high-volume AI applications where the difference between 89% and 91% on MMLU-Pro literally doesn't affect the end-user experience, DeepSeek V4 is a genuinely strong choice that I'd recommend without hesitation.
I plan to keep testing it over the coming weeks and I'll update this review if my assessment changes significantly. The Engram memory system in particular is something I want to evaluate more thoroughly over longer time horizons, because the real value of persistent memory only becomes clear after weeks of continuous use rather than the one week I've had so far.
For now, if you've been paying $2.50 per million input tokens (or more) and wondering whether there's a cheaper way that doesn't mean settling for a noticeably worse model, the answer is yes. DeepSeek V4 is that model, and the gap between it and the frontier is small enough that most of you won't notice it in your day-to-day work. Give it a try. At $0.30 per million tokens, the cost of finding out is basically nothing.