Some links on this site are affiliate links, meaning we may earn a small commission at no extra cost to you if you click through and make a purchase. This does not influence our reviews or recommendations — we only suggest tools we genuinely believe in.
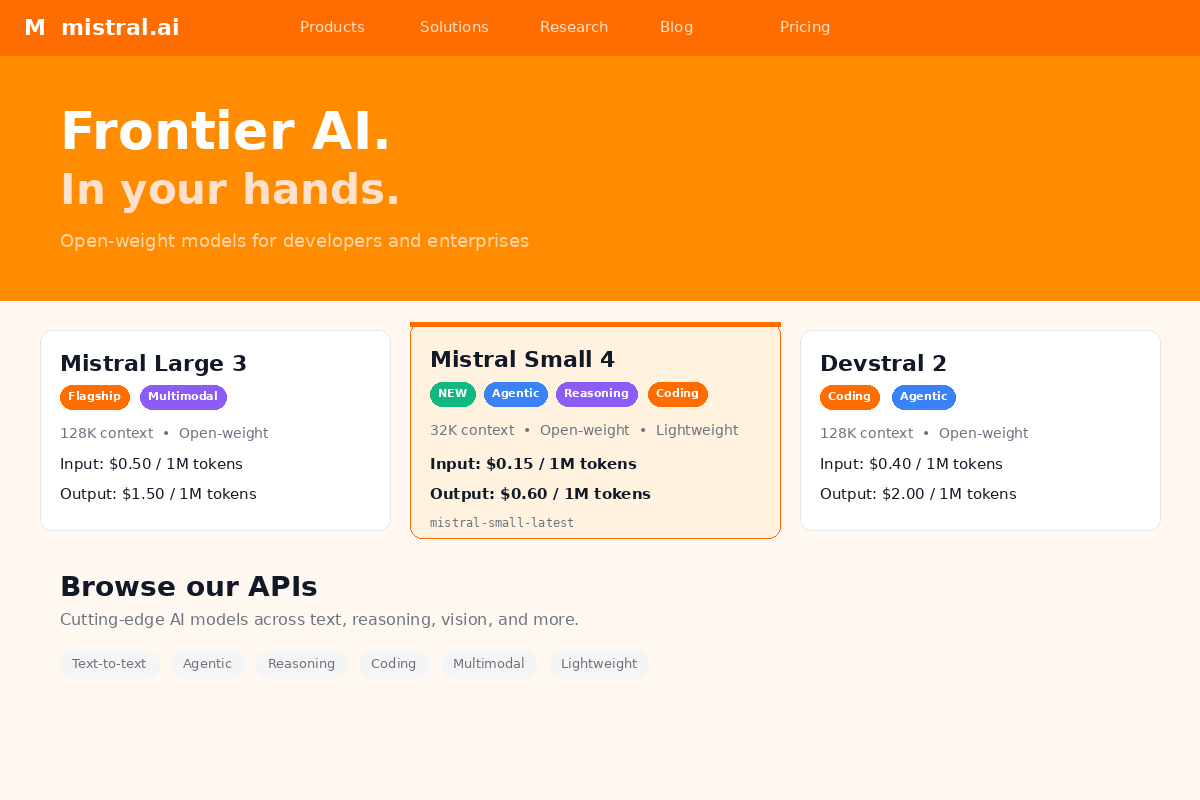
Mistral Small 4 launched on March 16, 2026, and it is honestly one of the more interesting releases to land this quarter, not because it tops every leaderboard — it does not — but because it represents a particular kind of bet that Mistral has been making for over a year now: that the most useful model for working developers and cost-conscious enterprises is not necessarily the smartest one on paper, but the one that gives you the best ratio of capability to cost while still letting you own and modify the weights.
What makes this release feel different from the usual open-weight drop is that Mistral Small 4 is not really one model — it is the result of merging three previously separate product lines into a single unified architecture, combining the Magistral reasoning engine, the Pixtral vision capabilities, and the Devstral coding specialization into one 119-billion-parameter mixture-of-experts model that only activates roughly 6 billion parameters per forward pass, all released under an Apache 2.0 license with a 256K context window.
This article walks through the architecture, the benchmark results (both the impressive ones and the ones where Mistral comes up short), the pricing, and how it compares head-to-head against the models you are most likely weighing it against.
What Is Mistral Small 4?
Mistral Small 4 is a 119-billion-parameter mixture-of-experts language model from Mistral AI, the Paris-based lab that has been steadily building out a full stack of open-weight models since its founding in 2023. The model uses a sparse MoE architecture with 128 experts, of which only 4 are active per token at inference time, meaning that while the total parameter count is 119B, the effective compute cost per forward pass is closer to what you would expect from a dense 6B model — which is a significant architectural advantage when you are thinking about deployment costs and throughput.
The release represents a strategic consolidation for Mistral, because rather than maintaining separate model lines for reasoning (Magistral), vision (Pixtral), and code generation (Devstral), they have folded all three capabilities into a single architecture. In practice, this means you no longer need to route requests to different endpoints depending on whether you are asking for code generation, image understanding, or multi-step reasoning — Mistral Small 4 handles all three natively, and the configurable reasoning parameter lets you control how much "thinking" the model does on a per-request basis.
The model was released under the Apache 2.0 license, which is the most permissive open-source license commonly used for AI models — there are no usage restrictions, no commercial limitations, and no requirement to share derivative works, which matters considerably for enterprises that want to fine-tune on proprietary data without worrying about license compliance. Mistral was also announced as a founding member of the NVIDIA Nemotron Coalition at GTC 2026, which positions the model within NVIDIA's broader ecosystem for open-weight model deployment and optimization.
The context window is 256K tokens, which is generous by open-weight standards and sufficient for most document analysis, codebase understanding, and multi-turn agentic workflows that developers are building today.
Key Features and Technical Specs
The architecture is worth understanding in some detail, because the specific choices Mistral made here explain both the model's strengths and its limitations.
The MoE design uses 128 total experts with 4 active per token. This is a higher expert count than most competing MoE models at this scale, and the sparse activation pattern means that each token only touches about 6 billion parameters during the forward pass. The practical consequence is that inference is fast and memory-efficient relative to the total parameter count — you get the knowledge capacity of a 119B model with compute costs that are closer to a small model, which is why Mistral can price the API so aggressively compared to dense models of similar capability.
The configurable reasoning feature is, in my view, the single most interesting design decision in this release. Mistral Small 4 exposes a reasoning_effort parameter that accepts four values: none, low, medium, and high. When set to none, the model skips chain-of-thought entirely and responds directly, which is ideal for simple classification, extraction, or routing tasks where thinking tokens would just add cost and latency without improving quality. When set to high, the model engages in extended multi-step reasoning similar to what you would get from a dedicated reasoning model. This per-request granularity is genuinely unusual — most competing models either always reason (like dedicated reasoning models) or never reason (like standard chat models), and switching between them requires routing to entirely different model endpoints.
The native multimodal support handles both text and image inputs, inherited from the Pixtral lineage. You can pass images directly into the model for visual question answering, document understanding, chart interpretation, and similar tasks without needing a separate vision model or preprocessing pipeline.
The 256K context window supports long-document analysis, large codebase ingestion, and extended multi-turn conversations. In practice, performance does degrade somewhat at the extreme end of the context window — as it does with virtually every model — but for the 32K-to-128K range that covers most real-world use cases, the context handling is solid.
On the efficiency side, sparse activation means the KV cache footprint is notably lighter than dense models of comparable total size, which translates to lower memory requirements for self-hosted deployments and better throughput on multi-tenant inference servers. Mistral reports a 40% latency reduction compared to Mistral Small 3 and roughly 3x higher request throughput, which are meaningful improvements for production workloads.
Performance Benchmarks
The benchmark picture for Mistral Small 4 is a mix of genuinely strong results and some areas where it clearly trails the competition, and I think being honest about both is more useful than cherry-picking the numbers that look best.
On AIME 2025, the standard math reasoning benchmark, Mistral Small 4 scores 83.8%. That is a strong result for an open-weight model at this price point, but it is worth noting that Google's Gemini 3 Flash scores 99.7% on the same benchmark, which is not really a gap you can explain away — Gemini simply dominates on pure mathematical reasoning. The comparison is somewhat unfair, of course, because Gemini 3 Flash is a proprietary model with likely far more compute behind it, but if raw math capability is your primary concern, you should know where the ceiling is.
On LiveCodeBench, which tests practical coding ability, Mistral Small 4 tells a more interesting story. It outperforms several larger competitors while using approximately 20% fewer output tokens to arrive at correct solutions, which means it is not just getting the right answer — it is getting there more efficiently, and in production coding workflows where you are paying per output token, that efficiency translates directly to cost savings.
The AA LCR (Agentic Accuracy at Low Character Rate) score of 0.72 at 1.6K characters is a metric worth paying attention to if you are building agentic workflows, because it measures how accurately the model completes tasks when constrained to brief outputs — and a score of 0.72 suggests the model is reasonably good at being concise without sacrificing correctness, which matters when you are chaining multiple agent steps together and want to minimize token overhead.
On broader knowledge benchmarks, MMLU-Pro comes in at 78.0% and GPQA at 71.2%. These are respectable but not chart-topping — Gemini 3 Flash hits 90.4% on GPQA, for instance, and several models in the 70B+ class score comparably on MMLU-Pro. The honest read is that Mistral Small 4 is a solid general-knowledge model that does not embarrass itself on any benchmark category, but it is not trying to be the smartest model in the room on raw intelligence — it is trying to be the most practical one.
The output token efficiency is perhaps the most underappreciated aspect of the benchmark results. Mistral reports that the model produces approximately 75% fewer tokens than some competitors when solving the same problems, and while that number will vary depending on the task, the general pattern is consistent: Mistral Small 4 tends to be concise, which makes it cheaper to run per-task even before you account for the lower API pricing.
Pricing — What Does Mistral Small 4 Actually Cost?
Pricing is where Mistral Small 4 makes its strongest case, and it is worth laying out the numbers clearly because they compare very favorably to essentially every alternative in its capability class.
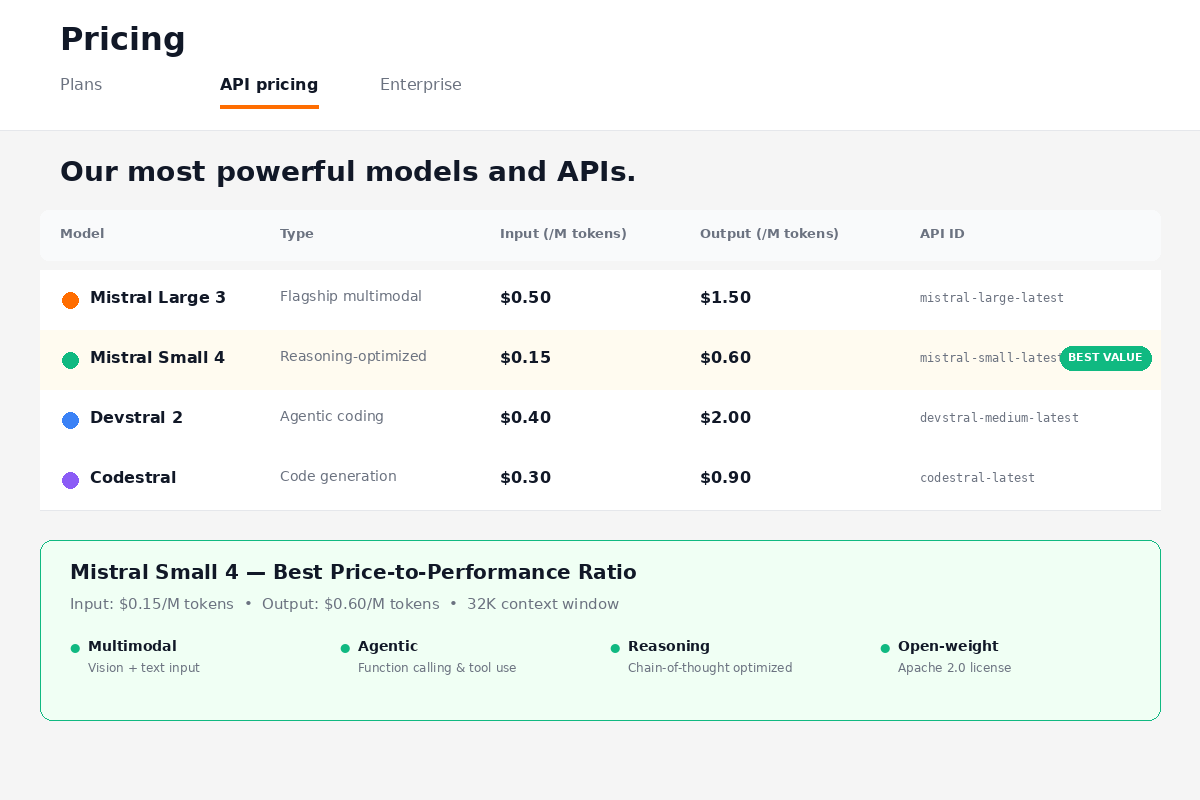
The API pricing through Mistral's hosted platform is $0.15 per million input tokens and $0.60 per million output tokens. Assuming a typical 3:1 input-to-output ratio (which is common for most chat and agentic workloads), that works out to a blended cost of roughly $0.26 per million tokens. That is genuinely inexpensive for a model at this capability level.
For comparison, Gemini 3 Flash prices at $0.50 per million input tokens and $3.00 per million output tokens — which means Mistral Small 4 is approximately 4.3x cheaper on input and 5x cheaper on output. The blended cost difference is even more dramatic for output-heavy workloads like code generation or long-form content creation, where the 5x output price gap really adds up.
Qwen 3.5 is priced around $0.20 per million input tokens and $0.80 per million output tokens through most providers, which makes it roughly comparable to Mistral Small 4 on input but about 33% more expensive on output.
For teams that want to experiment before committing, NVIDIA's build.nvidia.com platform offers free prototyping access to Mistral Small 4 through their NIM inference endpoints, which is a low-friction way to test the model against your specific use cases without any API costs.
And of course, because the model is released under Apache 2.0, self-hosting is entirely free from a licensing perspective — your only costs are the infrastructure itself. For organizations that already have GPU capacity (or are willing to invest in it), running Mistral Small 4 on your own hardware eliminates per-token costs entirely, which can be dramatically cheaper at scale compared to API pricing from any provider.
Mistral Small 4 vs Gemini 3 Flash
This is probably the comparison that matters most for teams evaluating Mistral Small 4, because Gemini 3 Flash is the model that most clearly dominates it on raw benchmark performance while occupying a similar "fast and capable" positioning in the market.
On the numbers, Gemini 3 Flash wins convincingly across most categories. AIME 2025 is 99.7% versus 83.8%. GPQA is 90.4% versus 71.2%. MMLU-Pro is higher for Gemini as well. These are not close contests on raw intelligence, and if benchmark scores are your primary selection criterion, Gemini 3 Flash is the better model, full stop.
But benchmark scores are rarely the only thing that matters in production, and this is where the comparison gets more nuanced. Mistral Small 4 is 4.3x cheaper on input tokens and 5x cheaper on output tokens, which means that for high-volume workloads — think thousands of API calls per day for classification, extraction, summarization, or agentic task completion — the cost difference can easily reach thousands of dollars per month. For a startup or a mid-size team running agentic workflows at scale, that pricing gap is not trivial.
The second major differentiator is openness. Mistral Small 4 gives you full access to the model weights under Apache 2.0, which means you can fine-tune it on your own data, deploy it on your own infrastructure, modify the architecture, and distribute derivative models without any restrictions. Gemini 3 Flash is proprietary — you use it through Google's API, and you have no ability to customize, self-host, or inspect the model's internals. For enterprises with data sovereignty requirements, regulatory constraints, or simply a preference for owning their AI stack, this distinction is decisive.
The third differentiator is the per-request reasoning toggle. With Mistral Small 4, you can set reasoning_effort to none for simple tasks and high for complex ones, all within the same model and the same API endpoint. With Gemini, toggling between "thinking" and "non-thinking" modes typically requires switching between different model variants or configurations, which adds complexity to your orchestration layer.
The honest summary: if you need the absolute best scores on reasoning and knowledge benchmarks, Gemini 3 Flash is better. If you need a model that is dramatically cheaper, fully open, and gives you fine-grained control over reasoning behavior on a per-request basis, Mistral Small 4 is the stronger choice.
Mistral Small 4 vs Qwen 3.5 122B
This is the most direct architectural comparison, because both Mistral Small 4 and Qwen 3.5 122B are open-weight MoE models released under Apache 2.0 with similar total parameter counts. They are, in many ways, the two models most likely to end up on the same shortlist for teams evaluating open-weight options in this size class.
On benchmarks, the comparison is mixed. Qwen 3.5 may have an edge on LiveCodeBench for certain coding tasks, and its larger active parameter count (10B active versus Mistral's 6B) gives it more per-token compute, which tends to help on tasks that require dense reasoning or knowledge retrieval. However, Mistral's lighter active footprint means faster inference and lower memory requirements, and the 6% lighter KV cache is a meaningful advantage for self-hosted deployments where memory is the binding constraint.
The context window difference is significant: Mistral Small 4 supports 256K tokens versus Qwen 3.5's 131K. For teams working with long documents, large codebases, or multi-turn agentic workflows that accumulate substantial context, that 2x gap in context length is a practical differentiator that matters in day-to-day use.
Both models are Apache 2.0, which means the licensing situation is identical — full commercial use, fine-tuning, and redistribution without restrictions. The choice between them is more likely to come down to which model performs better on your specific use case, which deployment ecosystem you prefer (Mistral has tighter NVIDIA NIM integration, while Qwen has broader community support in some regions), and whether the 256K context window matters for your workloads.
Mistral's configurable reasoning toggle is another differentiator here — Qwen 3.5 does not offer an equivalent per-request reasoning control, so if you want to dynamically adjust how much the model "thinks" depending on task complexity, Mistral Small 4 gives you that flexibility natively.
Mistral Small 4 vs GPT-OSS 120B
GPT-OSS 120B is the other model in this weight class that comes up frequently in comparisons, and the matchup is fairly straightforward. Both models sit at roughly 120 billion total parameters, and on AIME 2025 their scores are broadly comparable, suggesting similar mathematical reasoning capability.
The context window is a clear win for Mistral: 256K tokens versus GPT-OSS's approximately 128K. For agentic workflows, long-document understanding, or any use case where context length is a constraint, that 2x advantage matters.
Mistral's reasoning toggle is another feature that GPT-OSS does not match. With GPT-OSS, you get whatever level of reasoning the model decides to apply — there is no per-request parameter to control thinking depth. Mistral Small 4's reasoning_effort parameter gives you explicit control, which is valuable for cost optimization in production (set it to none for simple tasks, save the expensive reasoning for complex ones).
On the licensing side, both models have permissive open licenses, though the specific terms differ. Mistral's Apache 2.0 is arguably the more familiar and widely understood license in the open-source community, which can simplify legal review for enterprises.
The throughput comparison favors Mistral as well, thanks to the sparse activation pattern — activating 6B parameters per token versus a denser architecture means faster inference and better hardware utilization, particularly on NVIDIA GPUs where Mistral has invested in optimization through the NIM deployment pipeline.
Who Should Use Mistral Small 4?
Based on the benchmarks, the pricing, and the architectural choices Mistral has made, there are some clear use cases where this model is a particularly strong fit — and some where it is honestly not the right choice.
Developers building coding automation and SWE agents are probably the single best audience for this model. The Devstral coding heritage, the strong LiveCodeBench scores, the efficient output token usage, and the configurable reasoning toggle all align well with the kind of multi-step agentic workflows that modern AI-assisted development requires. If you are building a coding agent that needs to read a codebase, plan changes, write code, and verify results, Mistral Small 4's combination of 256K context, per-request reasoning control, and low token costs makes it a compelling backbone model.
Enterprises with data sovereignty and compliance requirements should take a close look, particularly those operating under GDPR or similar regulatory frameworks. Mistral AI is a French company subject to EU data protection law, which provides a level of regulatory familiarity that some enterprises prefer over models from US or Chinese labs. The Apache 2.0 license means you can self-host entirely within your own infrastructure, and the multimodal capabilities mean you can use it for document understanding workflows without needing to pipe sensitive documents through external vision APIs.
Researchers and fine-tuning practitioners benefit from the Apache 2.0 license and the MoE architecture, which makes the model an interesting substrate for experiments in expert routing, sparse activation patterns, and domain-specific fine-tuning. The open weights mean you can inspect, modify, and publish derivative work without any licensing friction.
Where Mistral Small 4 is not the right choice: if you are hoping to run this on consumer hardware — a gaming GPU or a MacBook — the 119B total parameter count means you need enterprise-grade infrastructure, realistically H100-class GPUs or equivalent cloud instances, to run inference at reasonable speeds. The model does not support audio input or output, so if you need speech-to-text or text-to-speech capabilities, you will need a separate pipeline. And if ultra-fast raw throughput is your single highest priority regardless of cost, larger proprietary models with more aggressive infrastructure optimization may still edge it out on pure speed, though Mistral's 40% latency improvement over Small 3 narrows that gap considerably.
How to Get Started
There are several deployment paths depending on your needs and infrastructure.
The fastest way to start is through the Mistral API or AI Studio, where you can access Mistral Small 4 immediately with the standard API pricing ($0.15/$0.60 per million tokens). This is the right choice if you want to prototype quickly without managing infrastructure, and the reasoning_effort parameter is available directly through the API.
For teams already in the NVIDIA ecosystem, NVIDIA NIM provides optimized deployment containers that handle quantization, batching, and inference optimization automatically. NIM deployments tend to deliver better throughput than vanilla self-hosted setups because NVIDIA has tuned the serving infrastructure specifically for their GPU architectures.
For self-hosting, the model weights are available on Hugging Face and work with the major open-source inference frameworks: vLLM for high-throughput serving, llama.cpp for CPU and mixed CPU/GPU inference on smaller setups, and SGLang for structured generation workloads. Each framework has tradeoffs in terms of throughput, latency, and ease of setup, but all three support the MoE architecture and can serve Mistral Small 4 in production.
Mistral has also released an eagle head for speculative decoding, which is a technique that can significantly improve inference speed by having a smaller "draft" model propose tokens that the main model then verifies in parallel. If you are deploying at scale and latency is a concern, speculative decoding is worth investigating — it typically improves throughput by 1.5-2x with minimal quality impact.
Verdict — 8.4/10
Mistral Small 4 is not the benchmark king of 2026. Gemini 3 Flash beats it on raw reasoning scores, Qwen 3.5 arguably matches or edges it on some coding benchmarks, and there are proprietary models that will outperform it on pure intelligence metrics. If your selection criterion is "which model gets the highest number on the most benchmarks," this is not your model.
But I think that framing misses the point of what Mistral has built here, because Mistral Small 4 is not trying to be the smartest model — it is trying to be the most useful one for developers and enterprises who need a model they can actually deploy, customize, and afford to run at scale. And on that criterion, the combination of open weights under Apache 2.0, per-request configurable reasoning, native multimodal support, 256K context, aggressive API pricing, and strong (if not chart-topping) benchmark performance across reasoning, coding, and knowledge tasks makes it one of the most well-rounded open-weight models available today.
The consolidation of Magistral, Pixtral, and Devstral into a single architecture is genuinely elegant from a developer experience perspective — one model, one endpoint, one set of weights to manage, with a simple parameter to control reasoning depth. That kind of simplicity has real value in production systems where every additional model endpoint is another thing to monitor, version, and maintain.
The enterprise hardware requirements are steep — you are not running this on a laptop — but they are justified by what you get in return, and for any team with access to H100-class GPUs (whether owned or rented), the cost-per-task math works out favorably compared to proprietary API pricing at moderate to high volumes.
I would give it an 8.4 out of 10: a strong, practical, well-balanced model that sacrifices a few points of benchmark prestige for meaningful advantages in cost, openness, and deployment flexibility. For many real-world use cases, that is exactly the right tradeoff to make.
Affiliate Disclosure: Some links in this article may be affiliate links. If you purchase a subscription through these links, StackBuilt AI may earn a small commission at no additional cost to you. We only recommend tools we have personally tested and believe in. Read our full affiliate disclosure.