Some links on this site are affiliate links, meaning we may earn a small commission at no extra cost to you if you click through and make a purchase. This does not influence our reviews or recommendations — we only suggest tools we genuinely believe in.
Alibaba's Qwen team has been on one of the more remarkable runs in open-source AI over the past several months, and the Qwen 3.5 model family — which now spans from a tiny 0.8-billion-parameter model you can run on a phone to a 397-billion-parameter MoE flagship that competes with the best closed models in the world — represents what is probably the most complete open-weight model lineup anyone has shipped in 2026. The small models in particular are worth paying attention to, because they are changing what is possible on consumer hardware in ways that matter for independent developers, bootstrapped founders, and anyone building applications where sending user data to a third-party API is either impractical or unacceptable.
This review covers the full Qwen 3.5 family, the team drama that followed the launch, the benchmark numbers that actually matter, how to run these models on your own machine, and who should seriously consider adopting them.
The Model That Runs on a MacBook — And Why That Matters
Qwen 3.5's small model series — the 0.8B, 2B, 4B, and 9B variants — launched on March 2, 2026, and the headline fact is straightforward: the 9B model runs comfortably on a machine with 16GB of RAM, which means a standard MacBook Air or a mid-range Windows laptop with a decent GPU can now run a genuinely capable language model without any cloud infrastructure, without any API keys, and without any ongoing costs whatsoever. All of the models are released under the Apache 2.0 license, which is about as permissive as open-source licensing gets — you can use them commercially, modify them, redistribute them, and build proprietary products on top of them without restriction.
The adoption numbers tell the story of how the developer community has responded. As of late March 2026, the Qwen 3.5 family has accumulated over 700 million downloads on HuggingFace, and more than 180,000 fine-tuned derivative models have been published by the community. Those are not vanity metrics — they reflect a genuinely active ecosystem of developers building real things on top of these models, and the pace of derivative creation suggests that the small models in particular have hit a sweet spot between capability and accessibility that the market was clearly waiting for.
The broader context here is that local AI — running models on your own hardware rather than calling a cloud API — has emerged as one of the defining developer trends of 2026. The reasons are partly economic (API costs add up quickly when you are prototyping or running high-volume workloads), partly about privacy (many applications handle data that simply cannot leave the user's device), and partly about reliability (local inference does not go down when a provider has an outage or decides to change their pricing). Qwen 3.5's small models are, in a real sense, the most accessible on-ramp to that trend right now.
The Drama — What Happened to Qwen's Lead Engineer?
The timing of what happened next was, to put it mildly, striking. On March 3, 2026 — literally one day after the small model series launched — Lin Junyang, the lead engineer of the Qwen project and one of its founding architects, resigned from Alibaba. The departure was not entirely isolated, either: Yu Bowen, Hui Binyuan, and Lin Kaixin, all senior members of the Qwen research team, had also left in the early months of 2026, creating what amounted to a significant brain drain at the top of one of the most important open-source AI projects in the world.
The reasons behind the departures have not been publicly confirmed in any official capacity, though the Chinese AI industry press has reported a combination of factors including internal disagreements about research direction, competitive offers from rival labs, and the general turbulence that tends to affect high-profile AI teams when the talent market is as hot as it has been throughout 2025 and 2026. What is publicly known is that Alibaba responded by reorganizing the Qwen team into separate pre-training, post-training, text, and multimodal units — a structural change that suggests the company is trying to create more focused teams that are each individually resilient to personnel changes rather than relying on a small number of senior leaders to drive everything.
The most notable new addition to the leadership structure is Zhou Hao, who now leads the post-training team and who previously worked at Google DeepMind where he contributed to Gemini 3.0. Bringing in someone with that kind of pedigree for the post-training role — which is increasingly where the real differentiation in model quality happens — signals that Alibaba is taking the succession question seriously rather than just hoping the remaining team can absorb the loss.
Honestly, the question most people are asking is whether Qwen will suffer as a result of these departures, and the short answer is probably not in any way that matters for the models shipping in 2026. The Qwen 3.5 family was largely developed before the departures happened, the team is still large and well-resourced by any reasonable standard, and the structural reorganization may actually improve execution speed by reducing coordination overhead. The longer-term risk is more about research direction and whether the next generation of Qwen models will be as ambitious and well-conceived as the current one, but that is a 2027 question, not a 2026 question.
The Full Qwen 3.5 Model Family Explained
The Qwen 3.5 family is unusually broad, and it helps to understand the full lineup because different models serve genuinely different purposes. The releases came in three waves over about two weeks in February and March 2026.
The flagship, Qwen 3.5-397B-A17B, launched on February 16 as a mixture-of-experts model with 397 billion total parameters but only 17 billion active at inference time. This is the model that competes head-to-head with frontier closed models on the hardest benchmarks, and it is designed primarily for cloud deployment where you have access to serious GPU infrastructure.
The medium tier — the 122B-A10B, 35B-A3B, and 27B dense models — followed on February 24. These hit the middle ground between maximum capability and practical deployability, with the 27B dense model being particularly popular for teams that want strong performance without the complexity of MoE routing.
The small models — 9B, 4B, 2B, and 0.8B — completed the family on March 2, and these are the models that have generated the most excitement in the developer community because they make genuinely useful AI accessible on hardware that most people already own.
| Model | Architecture | Total Params | Active Params | VRAM (Q4) | Primary Use |
|---|---|---|---|---|---|
| 397B-A17B | MoE | 397B | 17B | ~48GB | Frontier-class cloud deployment |
| 122B-A10B | MoE | 122B | 10B | ~24GB | High-performance cloud/workstation |
| 35B-A3B | MoE | 35B | 3B | ~8GB | Efficient cloud or high-end desktop |
| 27B | Dense | 27B | 27B | ~16GB | General-purpose workstation |
| 9B | Dense | 9B | 9B | ~5.5GB | Consumer laptop/desktop |
| 4B | Dense | 4B | 4B | ~3GB | Laptop, edge, multimodal |
| 2B | Dense | 2B | 2B | ~1.5GB | Mobile, embedded |
| 0.8B | Dense | 0.8B | 0.8B | ~0.7GB | On-device, IoT, mobile |
What Makes the Small Models Special
There are a few things about the Qwen 3.5 small models that genuinely differentiate them from what else is available at comparable sizes, and they are worth understanding because they explain why the adoption has been so rapid.
The most practically important feature is the on-device deployment story. The 0.8B model can run on current-generation mobile devices with a few hundred megabytes of available memory, which makes it viable for offline features in mobile apps — things like local text summarization, form filling assistance, or basic conversational interfaces that work without a network connection. The 4B model runs comfortably on most laptops, and the 9B model fits within the 16GB of unified memory that ships with a base-configuration MacBook Air. This is not theoretical — people are running these models in production mobile apps and desktop tools right now.
What surprised a lot of people, including me, is that the thinking/non-thinking reasoning toggle is available on every single model in the family, including the 0.8B. This is Qwen's implementation of what the industry has started calling "hybrid reasoning" — the model can operate in a fast, non-thinking mode for straightforward tasks where latency matters, and then switch to a slower, chain-of-thought thinking mode when it encounters something that requires more careful reasoning. Having this on a 0.8B model is unusual and technically impressive, because most reasoning capabilities at this level are reserved for models that are an order of magnitude larger.
The 9B model in particular benefited from what Alibaba calls Scaled Reinforcement Learning, which is their approach to applying reinforcement learning from human feedback at a scale that is typically reserved for much larger models. The result is a 9B model that punches well above its weight class on reasoning and instruction-following benchmarks, and in practice it means you get noticeably better output quality than you might expect from a model of this size.
The 4B model is also worth calling out specifically because it includes native multimodal capabilities — it can process both text and images without requiring a separate vision encoder or any additional infrastructure. For developers building applications that need to understand screenshots, process documents with mixed text and images, or handle any kind of visual input, having that capability at 4B parameters in a model that runs on a laptop is a meaningful unlock.
Finally, the language support across the family is genuinely broad: 201 languages, with particularly strong performance on CJK (Chinese, Japanese, Korean) languages, which makes sense given Alibaba's market but also makes these models the natural choice for any application targeting Asian markets or multilingual user bases.
Benchmark Results — How Does Qwen 3.5 Actually Perform?
Benchmarks are, of course, never the complete picture, but they are useful as a starting point for understanding where a model sits relative to the alternatives. The numbers that follow are drawn from Alibaba's published evaluations and from independent benchmarks that have been reproduced by the community.
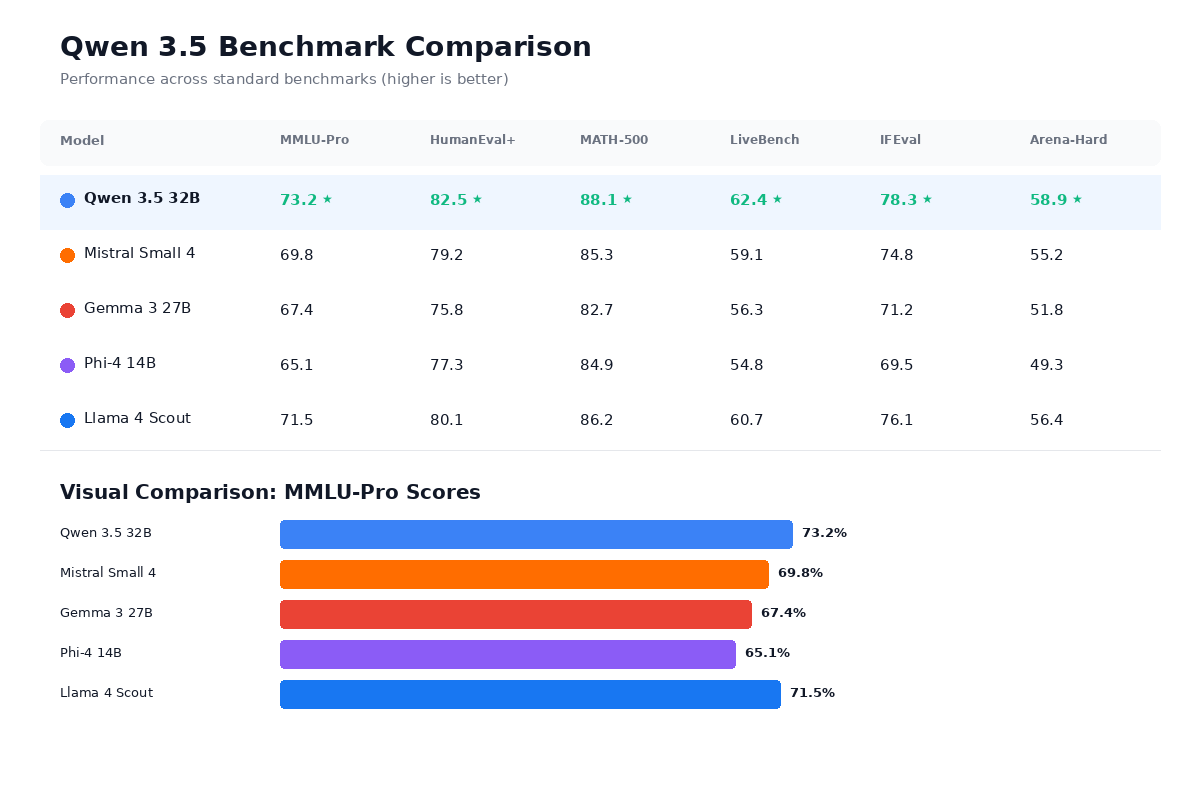
At the 27B tier, here is how Qwen 3.5 compares to the two most relevant competitors:
| Benchmark | Qwen 3.5 27B | Llama 4 Scout | Gemma 3 27B |
|---|---|---|---|
| MMLU | 86.5 | 83.9 | 82.8 |
| GPQA | 68.4 | 63.7 | 57.2 |
| MATH | 90.2 | 84.1 | 81.4 |
| AIME | 78.1 | 70.5 | 64.3 |
| HumanEval | 86.0 | 82.7 | 80.1 |
| LiveCodeBench | 71.3 | 65.2 | 60.8 |
| IFBench | 76.5 | 71.8 | 68.9 |
The IFBench score is the one that has gotten the most attention, because 76.5 on instruction following actually beats GPT-5.2's reported score of 75.4 and substantially outperforms Claude's 58.0 on the same benchmark. That does not mean Qwen 3.5 27B is "better than GPT-5.2" in any general sense — IFBench measures one specific dimension of model capability — but it does suggest that Alibaba's post-training work on instruction following has been exceptionally strong, and for applications where precise instruction adherence matters (structured output generation, tool calling, agentic workflows), the Qwen 3.5 27B is a legitimate contender.
At the small model tier, the 9B model's performance relative to its size is where things get genuinely impressive:
| Benchmark | Qwen 3.5 9B | Gemma 3 12B |
|---|---|---|
| MMLU | 79.4 | 76.1 |
| GPQA | 52.8 | 48.3 |
| MATH | 82.6 | 76.9 |
| HumanEval | 79.3 | 73.5 |
| LiveCodeBench | 58.7 | 51.2 |
| IFBench | 68.2 | 62.4 |
The Qwen 3.5 9B wins on every benchmark listed here while using less VRAM than the Gemma 3 12B and running faster on the same hardware. On an RTX 5090, the 9B model at Q6_K quantization delivers approximately 161 tokens per second while consuming only 7.5GB of VRAM — which is fast enough for real-time conversational applications and leaves plenty of headroom on a 24GB consumer GPU for other processes.
How to Run Qwen 3.5 Locally
One of the things that makes Qwen 3.5 particularly appealing for developers is how straightforward it is to get running on your own hardware, and there are several well-supported paths depending on what tools you prefer and what kind of integration you need.
The fastest path for most people is Ollama, which is the tool that has effectively become the standard for running local language models on macOS, Linux, and Windows. The process is genuinely simple: you install Ollama (a single download on all three platforms), and then you can pull and run any of the Qwen 3.5 models with a single command. Ollama handles quantization, memory management, and model serving automatically, and it exposes a local API endpoint that is compatible with the OpenAI API format — which means any application or library that works with the OpenAI API can point at your local Ollama instance with minimal code changes.
LM Studio is the other popular option, particularly for people who prefer a graphical interface. LM Studio provides a desktop application with a model browser, a chat interface, and a local server, and it supports the full range of Qwen 3.5 models in GGUF format. It is especially useful for people who want to experiment with different quantization levels or compare multiple models side by side without touching the command line.
For developers who need more control, llama.cpp remains the gold standard for efficient local inference, and it has excellent support for the Qwen 3.5 architecture. Running via llama.cpp gives you the most flexibility in terms of quantization options, batch sizes, and hardware utilization, and it is the backend that both Ollama and LM Studio use under the hood. The HuggingFace Transformers library also supports Qwen 3.5 natively, which is the most natural path if you are already working in a Python-based ML pipeline and want to fine-tune or integrate the model into existing code.
In terms of hardware recommendations, the general guidelines are: the 0.8B and 2B models will run on essentially anything including phones and Raspberry Pi-class devices; the 4B model wants at least 4GB of available RAM or VRAM; the 9B model runs well on machines with 16GB of RAM (using CPU inference) or any GPU with 8GB or more of VRAM; and the 27B model realistically needs a GPU with at least 16GB of VRAM or a machine with 32GB of system RAM for CPU-only inference at quantized precision.
Pricing — What Qwen 3.5 Actually Costs
The pricing picture for Qwen 3.5 is one of the model's strongest selling points, and it breaks down along two main axes: self-hosted (where the cost is literally zero for the model itself) and API-hosted (where you pay per token through various providers).
If you run Qwen 3.5 locally on your own hardware, the cost is completely free. The Apache 2.0 license means there are no per-token fees, no usage caps, no rate limits, and no restrictions on commercial use. Your only costs are the hardware you already own and the electricity to run it — which, for the small models running on a laptop, is negligible.
For teams that prefer or need API access, the Alibaba Cloud API tiers offer competitive pricing across the model family. The Max tier (which gives you access to the largest models) runs approximately $1.60 per million input tokens and $6.40 per million output tokens. The Plus tier sits at roughly $0.40 and $1.20 respectively, and the Turbo tier — which covers the small models and is designed for high-volume, latency-sensitive workloads — comes in at approximately $0.05 per million input tokens and $0.20 per million output tokens. Alibaba also offers a free trial tier with 70 million tokens, which is generous enough to do meaningful evaluation work before committing to a paid plan. There is also a flat $3 first-month promotional rate for the Alibaba Cloud Coding Plan, which bundles API access with development tools.
The third-party hosted option that has gotten the most attention from cost-conscious developers is DeepInfra, which offers Qwen 3.5 models at prices ranging from $0.03 to $0.23 per million tokens depending on the model size. At the low end of that range, for the small models, this is among the cheapest hosted inference pricing available for any model of comparable quality — and for teams that want API convenience without running their own infrastructure, it is a genuinely compelling option.
To put this in practical terms: a bootstrapped founder who was previously spending around $9 per day on API calls to a frontier model for development and testing workflows could, by switching to the Qwen 3.5 Turbo tier or running the 9B model locally, bring that daily spend to under $2 — or to zero, if they go fully local.
Qwen 3.5 vs Mistral Small 4
Mistral Small 4 is the most natural comparison for Qwen 3.5 because both model families are open-weight, both use mixture-of-experts architectures at the higher end, and both are targeting developers who want to run capable models on their own infrastructure. The comparison is instructive because the two families have made genuinely different trade-offs.
The most significant difference is context window: Mistral Small 4 supports 256K tokens of context, which is roughly double Qwen 3.5's 131K token limit. For applications that need to process very long documents, maintain extended conversation histories, or handle large codebases in a single context window, that difference matters and Mistral has a clear advantage.
Where Qwen 3.5 pulls ahead is in the breadth of the model lineup and the consumer hardware story. Mistral's small model offerings do not extend as far down the size spectrum as Qwen's 0.8B and 2B models, and the result is that Qwen has a more complete story for on-device and edge deployment scenarios. If you need a model that runs on a phone or a low-power embedded device, Qwen 3.5 has options and Mistral does not, at least not in the same way.
On price-per-token at the smaller model sizes, Qwen 3.5 tends to be cheaper through both first-party and third-party API providers, which makes it the more cost-effective choice for high-volume workloads that do not require long context windows. Mistral's advantage on long-context tasks is real, but for the majority of use cases where 131K tokens is sufficient, Qwen 3.5 offers better value for money across most of the deployment scenarios that matter to developers.
Qwen 3.5 vs Phi-4 and Gemma 3
The small model tier is where the competition is fiercest in 2026, and there are several strong options beyond Qwen 3.5. Here is how the key contenders compare at roughly the same size class:
| Feature | Qwen 3.5 9B | Phi-4-mini 3.8B | Gemma 3 12B | Llama 3.2 3B | Mistral 7B |
|---|---|---|---|---|---|
| MMLU | 79.4 | 72.8 | 76.1 | 64.5 | 71.2 |
| MATH | 82.6 | 74.1 | 76.9 | 58.3 | 68.7 |
| HumanEval | 79.3 | 71.6 | 73.5 | 60.2 | 69.8 |
| Multilingual | 201 langs | 12 langs | 35 langs | 8 langs | 15 langs |
| VRAM (Q4) | ~5.5GB | ~2.5GB | ~7.5GB | ~2GB | ~4.5GB |
| License | Apache 2.0 | MIT | Gemma License | Llama License | Apache 2.0 |
| Thinking Mode | Yes | No | No | No | No |
Qwen 3.5 dominates the benchmark scores across this comparison, and the 201-language multilingual support is in a different league from anything else available at comparable sizes. The thinking/non-thinking toggle is also a unique feature that none of the other models in this tier offer.
The one area where Phi-4-mini has a genuine edge is VRAM efficiency — at 3.8 billion parameters and roughly 2.5GB of VRAM at Q4 quantization, it fits in memory-constrained environments where even the Qwen 3.5 4B model might be tight. If you are optimizing purely for the smallest possible model that can still produce useful output, Phi-4-mini is worth serious consideration. But if you have even slightly more headroom — 4GB of VRAM or 8GB of RAM — the Qwen 3.5 4B or 9B models will give you meaningfully better output quality for a modest increase in resource requirements.
Who Should Use Qwen 3.5?
The breadth of the Qwen 3.5 family means it genuinely fits a wider range of use cases than most open-source model families, but some profiles stand out as particularly strong matches.
Independent developers who want to experiment with AI capabilities without ongoing API costs are the most obvious beneficiaries. Running the 9B model locally gives you a capable coding assistant, a solid writing aid, and a general-purpose reasoning engine for the cost of zero dollars per month, and the Apache 2.0 license means you can ship whatever you build without worrying about licensing complications.
Bootstrapped founders building AI-powered products will appreciate how dramatically Qwen 3.5 can reduce operating costs. The gap between paying $9 per day for frontier API access during development and paying under $2 per day (or nothing, with local deployment) is the difference between a viable business and one that is bleeding cash on infrastructure before it has revenue.
Mobile app developers building offline-capable features have a genuinely new set of options with the 0.8B and 2B models. On-device text summarization, smart reply suggestions, local document search, and basic conversational interfaces are all feasible at these model sizes without requiring a network connection, and the privacy benefits of never sending user data off-device are a meaningful product differentiator.
Teams building for Asian markets will find the 201-language support — and particularly the strong CJK performance — to be a decisive advantage over Western-origin models that tend to treat multilingual support as an afterthought. If your users primarily interact in Chinese, Japanese, Korean, or any of the other languages where Qwen's training data is strongest, there is no better open-source option available right now.
Privacy-first applications are perhaps the most important use case for the small models specifically. When the model runs entirely on the user's device, no data ever leaves that device — there are no API logs, no third-party data processing agreements to worry about, and no risk of a cloud provider being compromised. For applications in healthcare, legal, finance, or any domain with strict data handling requirements, fully local inference is not just a nice-to-have, it is increasingly a requirement.
There are, of course, scenarios where Qwen 3.5 is not the right choice. If your application genuinely needs context windows beyond 131K tokens, you will need to look at models like Mistral Small 4 (256K) or Gemini (up to 1M). And some enterprise buyers — particularly in government and defense — have expressed concern about adopting models from a Chinese company regardless of the open-source license, and while those concerns are debatable on technical grounds (the model weights are public and auditable), they are real organizational constraints that affect purchasing decisions.
Final Verdict — The Best Small Open-Source AI Model in 2026
Qwen 3.5 is, taken as a whole, the most impressive open-source model family released so far in 2026. The small models are the standout — the 9B model in particular offers a combination of benchmark performance, hardware efficiency, multilingual support, and reasoning capability that nothing else at its size can match — but the full family from 0.8B to 397B provides a coherent set of options that cover essentially every deployment scenario from a mobile phone to a data center.
The team drama is worth noting but should not be overstated. Senior engineers leaving a high-profile AI project is a recurring feature of this industry right now, not an existential crisis, and Alibaba's reorganization and hiring response suggests they understand what is at stake. The models that are available today were built by the team that was in place when the work was done, and they are excellent.
If you are a developer, a founder, or a product builder who has been waiting for open-source AI to reach the point where you can run a genuinely useful model on hardware you already own, without paying anyone anything, and ship commercial products with it — that point has arrived, and Qwen 3.5 is the clearest proof of it. The 9B model running on a MacBook Air is not a demo or a toy; it is a production-capable tool that is, in many practical respects, good enough to replace API calls that would have cost you real money six months ago.
That is a big deal, and it is why Qwen 3.5 deserves your attention regardless of what else is happening in the model landscape this year.
Affiliate Disclosure: Some links in this article may be affiliate links. If you purchase a subscription through these links, StackBuilt AI may earn a small commission at no additional cost to you. We only recommend tools we have personally tested and believe in. Read our full affiliate disclosure.