
OpenAI shipped two new models on March 17, 2026 – GPT-5.4 mini and GPT-5.4 nano – and the reaction from developers and regular users has been split right down the middle, which is genuinely interesting because these models are both very good and noticeably more expensive than what they replace. I have spent the past few days going through benchmarks, pricing tables, developer forums, and real-world reports to figure out what actually matters here, and I think the story is more nuanced than the typical “new model drops, everyone celebrates” cycle we have gotten used to.
This article covers what was released, who gets access to what, the benchmark numbers that matter, API pricing (and why the developer community is frustrated about it), and how GPT-5.4 mini and nano compare to Claude Haiku 4.5, Gemini 3 Flash, and other models you might already be using.

What Was Actually Released (and the Model Hierarchy You Need to Understand)
The GPT-5.4 family now has four tiers, and understanding how they relate to each other is worth a minute of your time before we get into the specifics, because OpenAI is clearly building toward a world where these models work together rather than competing with each other.
Here is the lineup, from largest to smallest:
- GPT-5.4 Pro – the maximum-performance model, available only to Pro, Business, Enterprise, and Edu ChatGPT plans
- GPT-5.4 (with Thinking mode) – the flagship, available to Plus and Team users, with a 1M token context window in the API
- GPT-5.4 mini – fast, near-flagship on coding and computer use tasks, with a 400K token context window and 128K max output, available to all ChatGPT tiers including Free and Go
- GPT-5.4 nano – the smallest and cheapest, designed for high-volume classification, extraction, and routing tasks, currently API-only
The idea – and Microsoft’s Azure blog articulated this most clearly – is that GPT-5.4 handles planning and high-stakes decisions, mini executes subtasks quickly (scanning codebases, processing screenshots, making API calls), and nano handles ultra-high-volume simple work like classification and routing. In practice, it is a team structure where the expensive model thinks and the cheaper models do the legwork.
Worth noting that this all landed remarkably fast: GPT-5.3 Instant shipped March 3, the full GPT-5.4 launched March 5, and mini and nano arrived March 17 – three major releases in about two weeks, which says a lot about the competitive pressure OpenAI is feeling right now.
What Free ChatGPT Users Get Now
This is the part that matters most to anyone who is not building software. If you are on ChatGPT’s Free or Go tier, you can now access GPT-5.4 mini by selecting the “Thinking” option in ChatGPT’s plus menu, and this is a genuinely significant upgrade over what free users had before.
Previously, free users had no direct access to GPT-5.4 level capabilities at all. Now the mini model – which approaches the flagship on several major benchmarks including coding and computer use – is available without paying anything. You also get it as an automatic fallback after hitting the GPT-5.3 rate limit (which is 10 messages per 5 hours on the Free tier), so even if you are not deliberately selecting it, you will likely end up using it.
What this changes in practice is that the gap between free and paid ChatGPT has narrowed considerably for single-turn questions and coding help. You still need a paid plan for the full GPT-5.4 with its 1M context window, GPT-5.4 Pro, and of course the higher rate limits – but for someone who uses ChatGPT a few times a day, the free tier just got a lot more capable, and I think that is going to make the upgrade decision harder for people on the fence about paying $20 a month.
The Benchmarks – Where Mini and Nano Actually Stand
Here is where things get interesting. GPT-5.4 mini is not a watered-down version of the flagship in the way that previous “mini” models sometimes felt – it is genuinely close to the full model on several important benchmarks, while the gap on others is larger than you might expect.
| Benchmark | GPT-5.4 (full) | GPT-5.4 mini | GPT-5.4 nano |
|---|---|---|---|
| SWE-Bench Pro (coding) | 57.7% | 54.4% | 52.4% |
| OSWorld-Verified (computer use) | 75.0% | 72.1% | 39.0% |
| GPQA Diamond (scientific reasoning) | 93.0% | 88.0% | 82.8% |
| Terminal-Bench 2.0 (terminal tasks) | 75.1% | 60.0% | 46.3% |
| Toolathlon (tool-calling accuracy) | 54.6% | 42.9% | 35.5% |
| MCP Atlas (multi-step tool use) | 67.2% | 57.7% | 56.1% |
| MMMUPro (vision/multimodal) | 81.2% | 76.6% | 66.1% |
Sources: Let’s Data Science, Hugging Face forums
The standout number is SWE-Bench Pro, where mini loses only about 3 points to the flagship (54.4% vs 57.7%), which means for most coding tasks the mini model is doing nearly identical work at a fraction of the cost. The OSWorld score of 72.1% for mini is also remarkable – that is close to the human performance baseline of 72.4%, and it means the mini model can autonomously operate desktop interfaces with near-human reliability.
Where the gap widens is terminal tasks (mini drops 15 points from the flagship) and tool-calling accuracy (down about 12 points), which suggests that if you are building complex agent pipelines where the model needs to reliably chain together multiple tool calls, the full GPT-5.4 is still worth the premium.
Nano has a different profile entirely. It is strong in scientific reasoning relative to its price tier (82.8% on GPQA Diamond is genuinely impressive for a model this cheap) but weak in autonomous computer use at 39.0% on OSWorld. Nano is not trying to be a general-purpose model – it is built for bulk classification, extraction, and routing where speed matters more than deep reasoning.
On raw speed, both models are fast. Developers on Hacker News reported GPT-5.4 mini averaging 180-190 tokens per second on the API, with nano hitting roughly 200 tokens per second. For context, Gemini 3 Flash runs at about 130 tokens per second – so both of these new OpenAI models are meaningfully faster than Google’s competing offering.

Here Is What It Costs – And Why Developers Are Not Happy
The pricing is where this gets complicated, and honestly, I had to double-check these numbers because the increase from the previous generation is larger than I expected.
| Model | Input (per 1M tokens) | Cached Input | Output (per 1M tokens) |
|---|---|---|---|
| GPT-5.4 mini | $0.75 | $0.075 | $4.50 |
| GPT-5.4 nano | $0.20 | $0.020 | $1.25 |
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5 mini (prev. gen) | $0.25 | $2.00 |
| GPT-5 nano (prev. gen) | $0.05 | $0.40 |
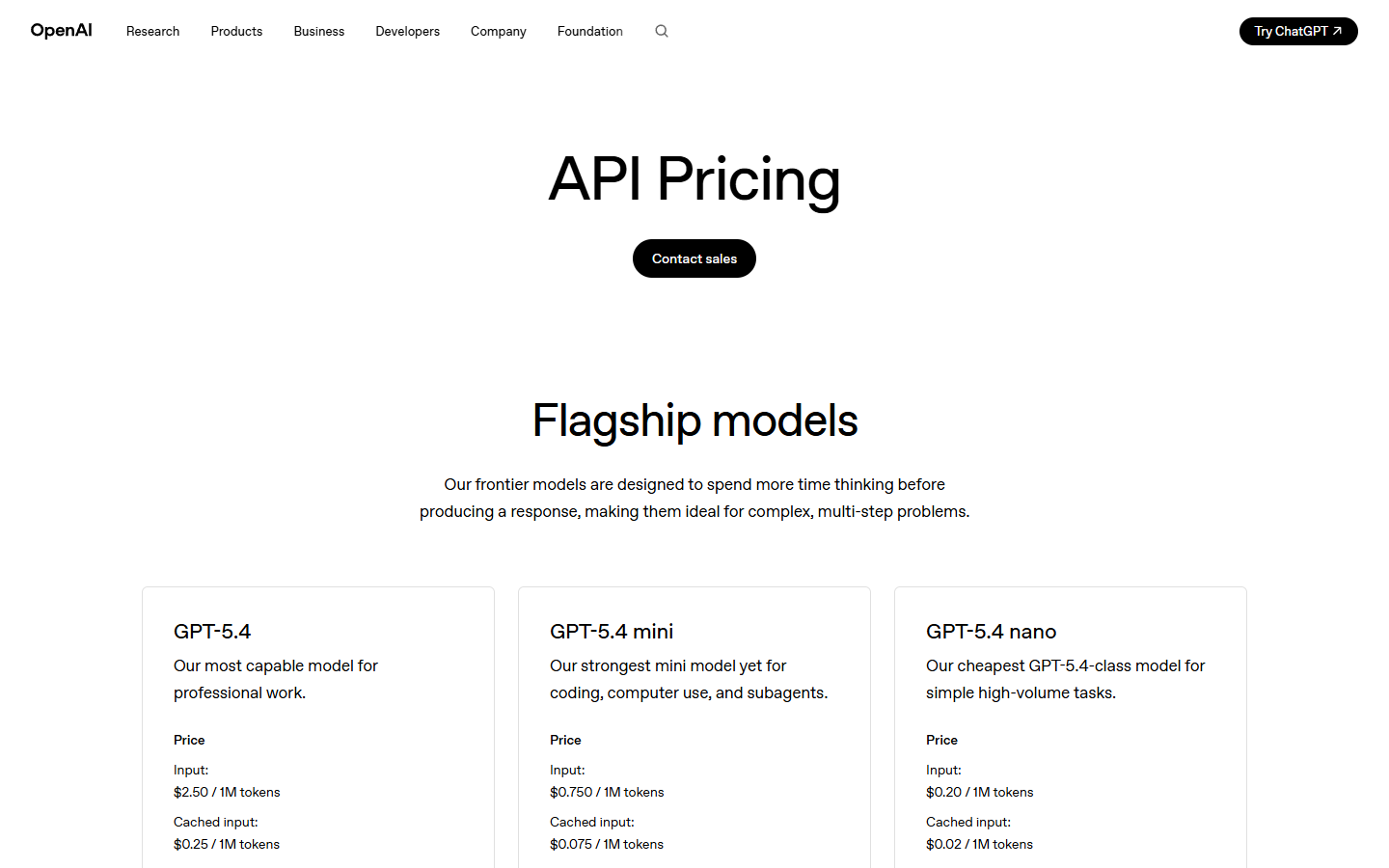
As Let’s Data Science pointed out, GPT-5.4 mini costs three times more per input token than GPT-5 mini, and GPT-5.4 nano costs four times more per input token than GPT-5 nano. This breaks a trend that had been consistent from 2023 through 2025 – every generation of small models got dramatically cheaper than the last. That is no longer the case.
The developer community has noticed. On Hacker News, one commenter laid it out plainly: “GPT 5 mini: Input $0.25 / Output $2.00 vs GPT 5.4 mini: Input $0.75 / Output $4.50 – models are getting more expensive and not actually getting cheaper.” On r/AI_Agents, a developer noted that the input price tripling “makes it very difficult to be a drop-in replacement” for existing pipelines built on GPT-5 mini pricing.
The counterargument – and I think it is a fair one – is that the price-per-capability ratio may still be favorable. If your coding pipeline goes from 46% accuracy to 54% accuracy, paying 3x more is probably worth it because the downstream cost of bad outputs compounds quickly. But for commodity tasks like image captioning or simple text classification (and one developer on r/OpenAI noted their classification pipeline ran at 70% accuracy on nano versus 80% on the full model at 12.3x lower cost), the added capability does not always justify the price increase.
This matters for the best vibe coding tools ecosystem too, because tools like Cursor and Windsurf that run GPT models under the hood will see their underlying API costs increase significantly for mini-tier usage, which could eventually pressure their own pricing or limit how aggressively they can call the model.
How They Compare to Claude Haiku, Gemini Flash, and the Competition
Here is the cross-provider comparison that I think most people actually want to see, because the real question is not whether GPT-5.4 mini is better than GPT-5 mini (it is) but whether it is the best option in its price class.
| Aspect | GPT-5.4 mini | Claude Haiku 4.5 | Gemini 3 Flash |
|---|---|---|---|
| Input price (per 1M tokens) | $0.75 | $1.00 | $0.50 |
| Output price (per 1M tokens) | $4.50 | $5.00 | $3.00 |
| Context window | 400K | 200K | 1M |
| Speed (tokens/sec) | 180-190 | N/A | ~130 |
| GPQA Diamond | 88.0% | 73.0% | 90.4% |
| OSWorld (computer use) | 72.1% | 50.7% | N/A |
| Terminal-Bench 2.0 | 60.0% | 41.0% | 47.6% |
Sources: DocsBot AI, Hacker News
Against Claude Haiku 4.5, GPT-5.4 mini wins on almost every measurable dimension – cheaper ($0.75 vs $1.00 input), twice the context window (400K vs 200K), and significantly better on computer use (72.1% vs 50.7%) and terminal tasks (60.0% vs 41.0%). Some developers on Hacker News still prefer Claude for agentic work, citing better instruction-following, but on paper the GPT-5.4 mini is the stronger model in most scenarios.
Against Gemini 3 Flash, the picture is more mixed. Flash is meaningfully cheaper ($0.50 vs $0.75 input, $3.00 vs $4.50 output) and has a 1M context window compared to mini’s 400K. It also slightly edges mini on GPQA Diamond (90.4% vs 88.0%). But GPT-5.4 mini is faster (180-190 tokens per second vs roughly 130) and better at terminal and computer use tasks. As one Hacker News commenter put it: “Mini: better than Haiku but not as good as Flash 3, especially at reasoning=none.”
For nano, the competition is Gemini 3.1 Flash-Lite at $0.25 per million input tokens, which is competitive on terminal benchmarks (51.7% vs nano’s 46.3%). I suspect the deciding factor for most developers will come down to which provider’s ecosystem they are already invested in. And it is worth keeping an eye on what Nemotron 3 Super and other open-weight models are doing here, because the pricing pressure from self-hosted models keeps pushing the floor lower.
Who Should Use Mini, Who Should Use Nano, and Who Should Stick with the Full Model
I will of course try to be straightforward here rather than giving the usual “it depends” answer.
Use GPT-5.4 mini if you are building coding assistants or agentic workflows where speed matters but you still need strong reasoning (that 54.4% SWE-Bench Pro score is hard to argue with at this price), if you are running computer use tasks where the 72.1% OSWorld score gives near-human reliability, or if you are a free ChatGPT user who simply wants the best available model without paying – just select “Thinking” in the plus menu.
Use GPT-5.4 nano if you are processing thousands or millions of simple tasks at scale – classification, extraction, routing – and the 200 tokens per second speed matters for your pipeline. Simon Willison’s example is a good reference point: describing 76,000 photos for $52 is the kind of economics nano enables.
Stick with the full GPT-5.4 if you are doing terminal-heavy agentic work (the 15-point gap on Terminal-Bench 2.0 is real), if you need the full 1M token context window, or if you are building complex multi-tool agent chains where tool-calling accuracy at 54.6% vs 42.9% is the difference between a workflow that runs reliably and one that fails intermittently.
And if you are a content creator or business owner who uses ChatGPT through the regular interface and you work with AI tools for content creators as part of your workflow, the honest answer is that you probably do not need to think about mini vs nano at all – just know the free tier got meaningfully better.
The Bottom Line
GPT-5.4 mini and nano are, I think, genuinely strong models that land in an awkward spot because of their pricing. The capability jump from the previous generation is real – mini approaches the flagship on coding and computer use, nano offers compelling economics for bulk tasks, and both are faster than their closest competitors. The fact that free ChatGPT users now get mini-level quality is a significant shift.
But the 3x price increase over GPT-5 mini is hard to ignore for developers who built production pipelines around the old pricing. For coding-heavy and computer use workloads, OpenAI’s bet that quality justifies cost looks reasonable. For commodity inference tasks – the simple classification and extraction work that was running on the old mini and nano – it is a harder sell, particularly when Gemini Flash and Flash-Lite sit right there at lower price points with competitive benchmark numbers.
The broader pattern is worth paying attention to: “better and cheaper” has quietly shifted to “better and more expensive,” and that changes the calculus for a lot of production workloads. I suspect we will see OpenAI adjust pricing within a few months if adoption disappoints, but either way, the era of every new model generation being automatically cheaper may be ending – at least from OpenAI.
Keep Reading
- NVIDIA Nemotron 3 Super Review 2026 – Another major model launch from the same week
- The 8 Best Vibe Coding Tools in 2026 – Many of these tools run on GPT models under the hood
- AI Tools for Content Creators – Practical tools for your creative workflow
