Some links on this site are affiliate links, meaning we may earn a small commission at no extra cost to you if you click through and make a purchase. This does not influence our reviews or recommendations — we only suggest tools we genuinely believe in.
On March 24, 2026, the ARC Prize Foundation published a set of results that cut through the hype cycle in a way that very few things have managed to do this year, and the numbers are stark enough that they deserve careful examination rather than a hot take: every single frontier AI model — GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6, Grok-4.20 — scored below 1% on the new ARC-AGI-3 benchmark, while untrained human participants scored 100%.
That is not a typo, and it is not a cherry-picked result from some obscure academic exercise. ARC-AGI-3 is the third iteration of what has quietly become the most important benchmark in artificial intelligence, a test designed specifically to measure the thing that most other benchmarks have failed to capture: whether an AI system can genuinely adapt to novel situations it has never seen before, or whether it is simply very good at pattern-matching against its training data.
This article walks through what ARC-AGI-3 actually is, how it works mechanically, why the scoring system is designed to resist the kinds of gaming that have made other benchmarks unreliable, and what the results honestly tell us — and do not tell us — about how close we are to artificial general intelligence.
The Headline That Shocked the AI World
The week of March 24-25, 2026 was one of those moments where the AI discourse fractured in a genuinely productive way, because the ARC-AGI-3 results landed at a moment when the industry narrative had been moving firmly in the direction of "AGI is basically here." Jensen Huang had been making increasingly confident claims about the arrival of artificial general intelligence, major labs were positioning their latest models as near-human-level reasoners, and the general tone in the space was that the remaining gaps were small and closing fast.
And then the numbers came out: Gemini 3.1 Pro scored 0.37%. GPT-5.4 scored 0.26%. Claude Opus 4.6 scored 0.25%. Grok-4.20 scored 0.00%. Humans, meanwhile, scored 100% — not experienced researchers, not trained participants, just regular people encountering the tasks for the first time.
The social media discussion was, of course, enormous. The results put $2 million in prize money on the table for anyone who can build a system that closes that gap, and they forced a genuine reckoning with the question of what we mean when we talk about intelligence in the context of AI systems. Because there is a real tension here between the daily experience that many of us have of these models being remarkably capable at specific tasks — writing code, drafting documents, analyzing data, answering questions — and the ARC-AGI-3 results suggesting that something fundamental is still missing.
The person at the center of all this is François Chollet, the creator of the Keras deep learning framework and the original architect of the ARC benchmark series, who has been making the case for years that the AI field's standard benchmarks are measuring the wrong things. ARC-AGI-3, in his framing, is the operationalization of an idea he first laid out in a 2019 paper called "On the Measure of Intelligence" — and if the results hold up under scrutiny, they suggest that the gap between current AI systems and genuine general intelligence is larger than the mainstream narrative acknowledges.
What Is ARC-AGI-3?
ARC-AGI-3 is a benchmark built around interactive game environments that have no instructions, no stated goals, and no rules given to the participant — human or AI. It was created by the ARC Prize Foundation, which is a collaboration between François Chollet and Mike Knoop, the co-founder of Zapier, and it was launched at Y Combinator's headquarters with a live fireside chat between Chollet and Sam Altman that drew significant attention.
To understand why ARC-AGI-3 matters, it helps to know where it came from. The original ARC-AGI-1 consisted of static visual puzzles — grid-based pattern completion tasks where the AI was given a few input-output examples and had to figure out the underlying transformation rule to produce the correct output for a new input. Those puzzles were clever, but they were static, which meant that sufficiently large models could eventually memorize patterns or brute-force solutions. ARC-AGI-2, released in March 2025, made the static puzzles harder but kept the same fundamental format.
ARC-AGI-3 is a fundamentally different kind of test. Instead of static puzzles, it presents the participant with interactive game environments — think of them as small, self-contained worlds where you can take actions and observe the results, but nobody tells you what the game is, what the goal is, or what the rules are. You have to figure all of that out through exploration and experimentation, and then you have to achieve whatever the implicit goal turns out to be.
The benchmark consists of 135 total environments: 25 that are publicly available for anyone to try, 55 that are semi-private (used for leaderboard evaluation but not publicly visible), and 55 that are fully private and reserved for final competition scoring. Across all of those environments, there are over 1,000 individual levels, all handcrafted by human game designers rather than generated algorithmically. The handcrafted nature is important because it means the environments are designed to be coherent and solvable through reasoning rather than through statistical shortcuts.

How ARC-AGI-3 Actually Works
The mechanics of ARC-AGI-3 can be broken down into four core cognitive tasks that the participant must perform, and it is honestly the combination of all four that makes it so difficult for current AI systems.
The first task is exploration — the participant is dropped into an environment with no information about what it is or how it works, and must interact with it to discover the basic mechanics. What happens when you move in a particular direction? What objects exist in this world? How do they behave when you interact with them? This is the equivalent of a child picking up a new toy and turning it over in their hands, pressing buttons to see what they do.
The second task is modeling — once the participant has gathered enough observations through exploration, they need to build an internal model of how the environment works. This means inferring the rules that govern the world, understanding cause and effect relationships, and developing expectations about what will happen when they take certain actions. This is not something you can do by memorizing patterns from training data, because the environments are genuinely novel.
The third task is goal acquisition — the participant has to figure out what they are supposed to be doing. There is no objective stated anywhere, no score counter visible at the top of the screen, no tutorial that explains the goal. The participant must infer from the structure of the environment and the feedback they receive what constitutes "success." In practice, this means recognizing implicit reward signals and understanding what the game designers intended.
The fourth task is planning and execution — once the participant understands the rules and the goal, they must devise and execute an efficient strategy to achieve it. This is where the scoring system becomes especially important, because it is not enough to eventually stumble into the solution through random actions — the benchmark specifically measures how efficiently the participant reaches the goal relative to a human baseline.
All of the environments are built on what Chollet calls "Core Knowledge priors" — the basic cognitive building blocks that humans share regardless of culture or education. These include an understanding of objects as discrete entities, basic geometry and spatial relations, simple counting, and the idea that objects persist even when you are not looking at them. The environments do not require specialized knowledge, domain expertise, or training. They are specifically designed so that any reasonably competent human adult can figure them out through common-sense reasoning alone.
This is a critical design choice, because it means that performance on ARC-AGI-3 cannot be attributed to knowledge gaps. When a frontier model scores 0.25% and a human scores 100%, the issue is not that the model does not know enough facts — it is that the model cannot adapt to genuinely novel situations the way humans can, even when those situations only require the most basic cognitive capabilities.
Every single environment in the benchmark has been validated by at least two out of ten untrained human participants, meaning that a person who has never seen the environment before was able to figure it out and solve it. This ensures that the test is fair and that the difficulty comes from novelty rather than from obscure or unintuitive design.
The Scoring System That Cannot Be Gamed
One of the most thoughtfully designed aspects of ARC-AGI-3 is the scoring metric, which is called RHAE — Relative Human Action Efficiency. The formula is straightforward but its implications are profound:
Score = (human actions / AI actions)²
The human baseline is set as the second-best performance out of ten first-time human players, which avoids both the problem of setting the bar too high (using an expert) and too low (using an average that might include confused or distracted participants). So if the human baseline for a particular environment is 10 actions to reach the goal, and the AI takes 100 actions, the score would be (10/100)² = 0.01, or 1%.
The squared term is the key design decision here, and it is what makes brute-force approaches essentially worthless. In a linear scoring system, an AI that took 10 times as many actions as a human would score 10% — not great, but not terrible. With the squared penalty, that same AI scores 1%. An AI that takes 30 times as many actions as a human scores 0.11%. The penalty escalates so steeply that any approach relying on trial and error, random exploration, or exhaustive search is going to score close to zero regardless of whether it eventually finds the solution.
The score is also capped at 1.0, meaning that an AI which happens to find a more efficient path than the human baseline does not get bonus points. This is intentional — the benchmark is not trying to measure whether AI can be superhuman at specific tasks, which we already know it can. It is trying to measure whether AI can match the basic human ability to figure out novel situations, and the cap ensures that the score reflects that specific capability rather than rewarding raw computational power on tasks that happen to be amenable to optimization.
The result is a scoring system where the only way to achieve a high score is to actually understand the environment in a way that allows for efficient, purposeful action — which is exactly what the benchmark is designed to test.
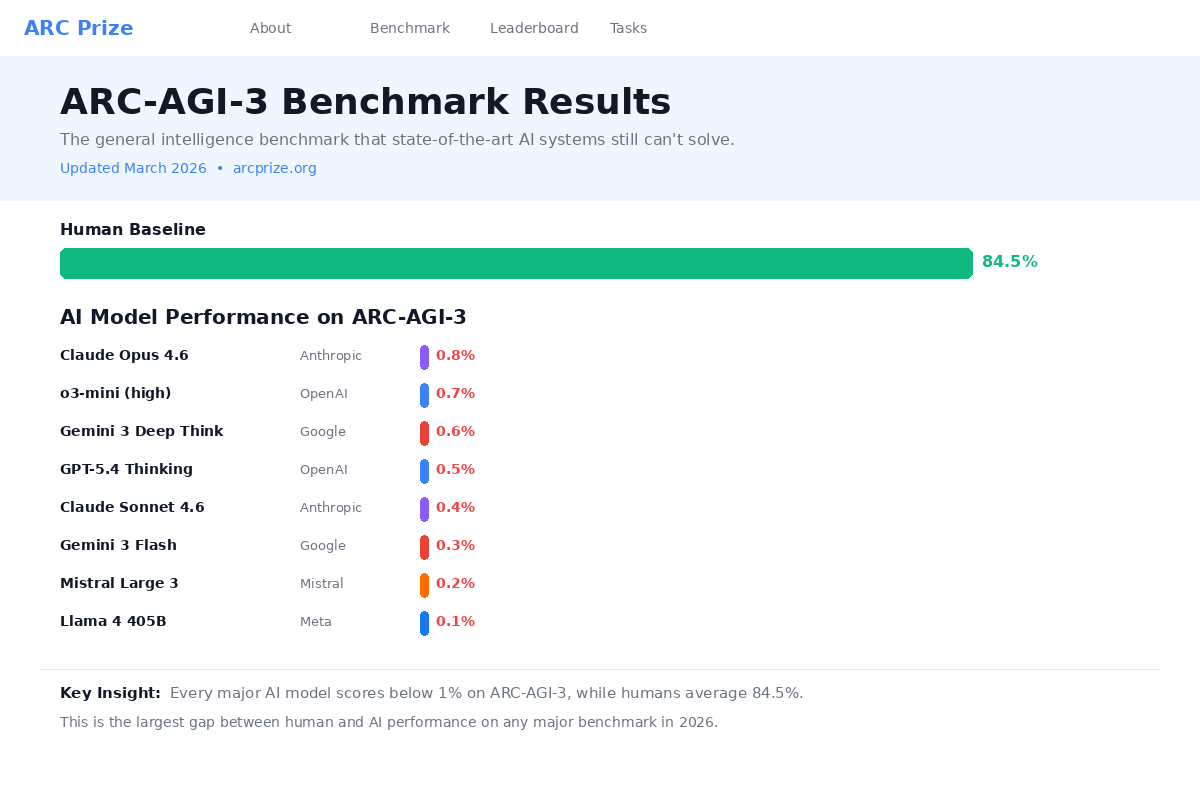
The Results — Every Major AI Model Ranked
Here are the headline results from the initial ARC-AGI-3 evaluation, including both the frontier model scores and the community leaderboard standings:
| Model / Participant | ARC-AGI-3 Score | Type |
|---|---|---|
| Human Baseline | 100% | Human (untrained) |
| StochasticGoose (community) | 12.58% | CNN + RL (non-LLM) |
| Gemini 3.1 Pro | 0.37% | Frontier LLM |
| GPT-5.4 | 0.26% | Frontier LLM |
| Claude Opus 4.6 | 0.25% | Frontier LLM |
| Grok-4.20 | 0.00% | Frontier LLM |
There are a few things worth calling out in these results. The first is that the top three entries on the community leaderboard are all non-LLM approaches — the leading entry, StochasticGoose, uses a convolutional neural network combined with reinforcement learning rather than a large language model. At 12.58%, it is still far from human performance, but it is more than 30 times higher than the best frontier LLM score. That is a genuinely significant finding, because it suggests that the architectural approach of large language models may be fundamentally ill-suited to this type of task, and that different approaches — even relatively simple ones by modern standards — can do meaningfully better.
The second thing worth noting is a result that did not make the headline numbers but is arguably more revealing. When researchers gave Claude Opus 4.6 a custom-built harness — essentially a specialized scaffolding system designed to help the model interact with environments it had already seen — the model scored 97.1% on known environments. But on unknown environments, the same model with the same harness scored 0%. That gap between 97.1% and 0% is, in many ways, the single most important result from the entire benchmark, because it proves concretely that task-specific scaffolding is not the same thing as general intelligence. The model is not struggling because it lacks capability in some abstract sense — it is struggling because it cannot transfer what it knows to situations it has not been specifically prepared for.
For historical context, the trajectory across the three ARC-AGI versions is also telling. On ARC-AGI-1, OpenAI's o3 model achieved roughly 87%. On ARC-AGI-2, the top score was around 24%. On ARC-AGI-3, the best frontier model score is 0.37%. Each version has increased the difficulty not by making the underlying tasks harder in absolute terms — humans still score 100% — but by making it progressively more difficult for AI systems to rely on memorization, pattern-matching, and brute force rather than genuine understanding.
Why This Is Different From Every Other Benchmark
The AI field has a well-documented benchmark problem, and it is worth understanding exactly how ARC-AGI-3 addresses it, because the pattern has repeated itself many times over the past few years. A benchmark is created to test some aspect of AI capability — MMLU for general knowledge, HumanEval for code generation, various math competitions for reasoning. Models initially score modestly. Then, through a combination of training on benchmark-similar data, prompt engineering, and architectural improvements, scores climb rapidly. Eventually the benchmark gets "saturated" — models score at or near 100% — and the benchmark loses its ability to discriminate between systems, at which point the field moves on to a new benchmark and the cycle repeats.
ARC-AGI-2 itself showed signs of this pattern. When it launched, the top AI score was around 3%. Within a year, scores had climbed to approximately 50%. That rapid improvement was not necessarily because models had become genuinely more intelligent in the interim — in many cases, it was because researchers had developed clever scaffolding, prompt engineering techniques, and fine-tuning strategies specifically targeted at the benchmark format.
ARC-AGI-3's interactive format is designed to resist this cycle in a fundamental way. Because the environments are interactive rather than static, they cannot be memorized. Because there are no stated rules or goals, there is no fixed prompt structure to optimize against. Because the scoring system penalizes inefficiency so heavily, brute-force approaches that work by trying many strategies and keeping the one that works are essentially useless. And because the private evaluation set contains environments that no participant — human or AI — has ever seen, there is no way to train specifically for the test.
The distinction that Chollet and the ARC Prize Foundation are drawing here is between being "trained for many tasks" and possessing "general intelligence." A model that has been trained on millions of code examples, mathematical proofs, and logic puzzles can appear highly intelligent when tested on tasks that resemble its training data, but ARC-AGI-3 is specifically designed to test what happens when you remove that resemblance entirely. What remains when the model encounters something genuinely new?
What ARC-AGI-3 Actually Measures
To understand what ARC-AGI-3 is really getting at, it helps to go back to Chollet's 2019 paper "On the Measure of Intelligence," because ARC-AGI-3 is essentially the practical implementation of the theoretical framework laid out in that paper. Chollet's central argument was that intelligence should not be measured by accumulated skills — by how many things a system can already do — but by skill-acquisition efficiency: how quickly and reliably a system can learn to do new things it has never encountered before, given only a minimal set of prior knowledge.
This is a fundamentally different way of thinking about intelligence than the one that drives most AI benchmarks, and it maps onto a real distinction that most people intuitively understand. We do not consider someone intelligent primarily because they know a lot of facts — we consider them intelligent because they can figure out new things quickly, adapt to unfamiliar situations, and solve problems they have not been explicitly trained to solve. A child who has never played chess but figures out the rules by watching a few games and then plays competently within an hour is demonstrating a kind of intelligence that is qualitatively different from a database that contains every chess game ever played.
ARC-AGI-3 operationalizes this distinction through its interactive format. The environments are designed so that no amount of pre-existing knowledge — no matter how vast the training corpus — provides a direct advantage. What matters is the ability to explore, model, infer goals, and plan efficiently in a genuinely novel context. And by that measure, current frontier AI systems are not close to human-level performance.
This also explains the "harness problem" that the Claude 97.1% vs. 0% result illustrates so clearly. In practice, much of the impressive performance we see from frontier AI models is the result of careful scaffolding — systems of prompts, tools, and workflows that are designed to help the model perform well on specific categories of tasks. That scaffolding is genuinely useful, and it is a real engineering achievement, but it is not the same thing as general intelligence. When the scaffolding encounters a task category it was not designed for, performance collapses to near zero, and that is exactly what ARC-AGI-3 is designed to reveal.
So — Are We Close to AGI?
The honest answer, based on the ARC-AGI-3 results, is that we are not close to AGI as Chollet defines it — which is to say, we are not close to building systems that can match the human ability to adapt to genuinely novel situations using only basic prior knowledge. The gap between 0.37% (the best frontier model) and 100% (untrained humans) is not a gap that incremental improvements are likely to close, because the issue does not appear to be one of scale or training data volume but rather one of fundamental approach.
The counterargument, of course, is that scores on previous ARC-AGI versions climbed rapidly after initial publication, and there is precedent for believing the same will happen with ARC-AGI-3. The community leaderboard already shows a non-LLM approach at 12.58%, which is orders of magnitude better than the frontier LLM scores and suggests that the problem is tractable if approached differently. It is entirely possible that within a year, clever researchers will have developed techniques that push scores to 30%, 50%, or higher.
But there is an important distinction to draw here. If those improvements come from developing genuinely new learning architectures that can adapt to novel environments — if someone builds a system that actually learns to play unfamiliar games the way humans do — that would be a real breakthrough toward AGI. If they come from developing increasingly sophisticated scaffolding that is specifically designed to perform well on the ARC-AGI-3 format, that would be a repeat of the pattern we have seen with every other benchmark, and the ARC Prize Foundation would presumably respond by developing ARC-AGI-4.
What crossing the 100% threshold would actually mean is worth thinking about, because it would imply the existence of a system that can match untrained human performance at figuring out novel interactive environments — which would be a genuinely remarkable capability with implications far beyond the benchmark itself. A system that can reliably figure out the rules, goals, and optimal strategies for any new interactive environment it encounters would be demonstrating something qualitatively different from anything current AI systems can do.
In the meantime, the honest framing is probably this: current AI is extremely capable at a wide range of specific tasks, and for most practical purposes — building software, writing content, analyzing data, automating workflows — those specific capabilities are genuinely valuable and continue to improve. But the kind of fluid, general-purpose adaptability that humans take for granted when encountering genuinely new situations is still missing, and ARC-AGI-3 provides the clearest evidence yet of exactly how large that gap remains.
How to Play ARC-AGI-3 Yourself
One of the best things about ARC-AGI-3 is that it is genuinely accessible. The 25 public environments are available for free in your browser at arcprize.org, and honestly, playing them yourself is the fastest way to understand why this benchmark is so effective — because you will almost certainly be able to solve environments that the most advanced AI systems on the planet cannot, and that visceral experience of "this is easy for me but impossible for GPT-5.4" is more illuminating than any number of articles about the topic.
If you are a developer or researcher interested in building solutions, there is API access available with free rate limits that allow you to submit agents and evaluate their performance against the semi-private environment set. The full competition — with $2 million in prize money — is hosted on Kaggle and is free to enter, and the prize structure is designed to reward genuine breakthroughs rather than incremental improvements.
For builders and creators who are not planning to compete but want to understand the benchmark, the public environments are the place to start. They take a few minutes each, they require no technical background, and they provide an intuitive sense for what "general intelligence" means in a way that reading about it simply cannot.
The Most Important Benchmark in AI Right Now
The reason ARC-AGI-3 matters beyond the research community is that it directly affects how we should think about evaluating and choosing AI tools. If you are building a product, running a business, or creating content with AI tools, the ARC-AGI-3 results are a useful corrective to the marketing narratives that surround every major model release, because they remind us that "this model scores 95% on benchmarks" does not necessarily mean "this model can handle any task you throw at it."
In practice, the distinction that ARC-AGI-3 highlights — between systems that are highly capable within their training distribution and systems that can genuinely adapt to novel situations — maps directly onto the experience that many builders have when working with AI tools. The model works brilliantly when the task resembles something it has seen before, and it struggles or fails silently when the task is genuinely novel. Understanding that distinction helps you make better decisions about where to rely on AI and where to maintain human oversight, which tools to invest in for which use cases, and how much trust to place in AI-generated outputs in situations where the stakes are high.
For the broader AI ecosystem, ARC-AGI-3 serves as a grounding mechanism — a benchmark that cannot be gamed through training data contamination, prompt engineering, or task-specific scaffolding, and that provides a clear, quantitative measure of a capability that genuinely matters. Whether you think AGI is five years away or fifty, the existence of a benchmark that can reliably measure progress toward that goal is valuable, and the fact that current systems score below 1% on it is information worth taking seriously as we make decisions about how to build with, invest in, and regulate AI systems in the years ahead.
Affiliate Disclosure: Some links in this article may be affiliate links. If you purchase a subscription through these links, StackBuilt AI may earn a small commission at no additional cost to you. We only recommend tools we have personally tested and believe in. Read our full affiliate disclosure.